第十四章:打砖块AI编程
在第十三章内容中,我们学习了用贪吃蛇游戏做为AI环境,用DQN来作为AI引擎,去驱动贪吃蛇自动找果实吃。本章我们将实现一个相同设计的程序,只不过是将贪吃蛇游戏换成打转块游戏,之前的AI部分不会有很多的改变。我们仍然会有三部分的代码文件来实现这个编程功能,第一部分代码是改造之前的打砖块游戏程序,第二部分代码是将之前贪吃蛇的AI引擎移植过来,做一点少许的修改。第三部分代码是构造一个函数来组装所有的逻辑,让所有的东西跑起来。下面就让我们开始吧。
一、打砖块环境改造
环境改造思路
先回顾一下打砖块游戏程序的代码结构是怎么样的。
classDiagram
Game *-- Ball : Composition
Game *-- Bat :Composition
Game *-- Brick : Composition
class Game {
ball
bat
brick
...
}
class Ball {
}
class Bat {
}
class Brick {
}
我们的代码定义了四个类,分别对应了球、球板、砖块以及游戏机制这四个模块。前三个类都使用初始化方法来加载图片资源,这三个类都拥有绘图draw方法。然后球和球板类是拥有update方法,用于更新其位置。最后一个类,也是最重要的是游戏机制即Game类,它在初始化过程中,将一些重要数据进行了初始化。然后在play函数中构造了游戏主循环。
对于人工操作的游戏,我们需要修改四个主要的方面。这些修改的地方和贪吃蛇是差不多的。
- 修改游戏重启机制
- 提供奖励、状态等游戏信息
- 增加决策函数,修改球板控制逻辑
- 修改核心运行机制,改造成单步运行
第一项是修改重启机制。在人工操作的游戏结束后,会将球重新放置在相同的起始位置以相同的角度出发,但是在AI算法训练中,我们希望球能在随机的位置出发,开始重新一局。
第二项是要提供游戏信息。人工操作游戏时,我们只需要用肉眼来观察显示器上的图片就可以了。但是在AI算法训练时,我们需要设计一些有用的信息发送传出去。
第三项是修改球板控制逻辑。人工操作游戏是通过鼠标来控制球板运动的,但在AI算法控制游戏时,我们要把检测输入逻辑进行修改,要修改成依赖AI的动作。
第四项是修改成单步运行游戏。为了和AI引擎配合,需要将play函数改造成单步运行。
改造代码实现
首先我们来实现第一项修改。编写一个新的函数reset,它负责在游戏重新开始时,将一些游戏数据进行重置,同时也实例化了新的球板、砖块和球这三种对象。这个函数会用在game类的初始化函数中,也会用在后续介绍的组装代码中。
def reset(self):
self.bat = Bat()
self.ball = Ball(self.Win_width)
self.bricks = Bricks()
self.score = 0
self.reward = 0
然后考虑第二项修改,我们需要提供三种信息给AI进行计算。 - 奖励数据 reward - 状态数据 state - 本轮游戏是否结束 game_over
首先考虑正值的reward,也就是当成功的用球板拦截住球的时候,我们把reward设置为10。这个逻辑我们放在bat_collision函数中,其它主要内容和之前的一致。
def bat_collision(self):
if self.ball.rect.colliderect(self.bat.rect):
self.reward = 10
self.ball.rect.bottom = self.bat.rect.top
diff_x = self.ball.rect.centerx - self.bat.rect.centerx
diff_ratio = min(0.95,abs(diff_x)/(0.5*self.bat.rect.width))
theta = asin(diff_ratio)
self.ball.speedX = self.ball.speed * sin(theta)
self.ball.speedY = self.ball.speed * cos(theta)
self.ball.speedY *= -1
if (diff_x<0 and self.ball.speedX>0) or (diff_x>0 and self.ball.speedX<0):
self.ball.speedX *= -1
我们还需要提状态数据,这里的状态信息计算比较简单,只计算球的中心横轴位置相对于球板两端的关系。
def get_state(self):
states = [
self.ball.rect.centerx<self.bat.rect.left-self.bat.rect.width,
self.ball.rect.centerx<self.bat.rect.left,
self.ball.rect.centerx>self.bat.rect.right,
self.ball.rect.centerx>self.bat.rect.right+self.bat.rect.width,
self.ball.rect.centerx>self.bat.rect.centerx
]
return np.array(states, dtype=float)
再来看第三项修改,在行动决策方面,我们不再需要用鼠标来控制球板运行,因此bat类的update函数会更为简单。它只负责基于speedX来更新球板的位置。
def update(self,win_width):
self.positionX += self.speedX
if self.positionX < 0:
self.positionX = 0
if (self.positionX > win_width - self.rect.width):
self.positionX = win_width - self.rect.width
self.rect.topleft = (self.positionX, self.positionY)
此外是增加handle_action函数来控制speedX的大小,以此来控制球板的方向,action的取值是三个方向选项,保持不动、向左、向右。
def handle_action(self, action):
if action==0:
self.bat.speedX = 0
elif action==1:
self.bat.speedX = -6
else:
self.bat.speedX = 6
self.bat.update(self.Win_width)
第四项需要修改的是play_step函数。这个函数负责游戏运行一个迭代的所有运算。hand_action来输入AI决策,ball.update来更新球的位置,bat_collision和bricks_collision来判断球板和砖块的碰撞。如果球掉落未被球板接住,check_failed函数会返回逻辑真值,此时将奖励值reward设置为-10。
def play_step(self,action):
game_over = False
self.reward = 0
for event in pygame.event.get():
if event.type == QUIT:
pygame.quit()
sys.exit()
self.handle_action(action)
self.ball.update(self.Win_width)
self.bat_collision()
self.bricks_collision()
if self.check_failed():
game_over = True
self.reward = -10
return self.reward, game_over, self.score
if len(self.bricks.contains)==0:
self.reward = 10
game_over = True
return self.reward, game_over, self.score
self.draw()
self.Clock.tick(60)
return self.reward, game_over, self.score
改造后的完整代码参考brick_env.py文件。
二、AI引擎的设计和编写
这里仍然使用基于DQN的AI引擎来玩游戏,所以此处的AI算法代码和上一章是类似的。打砖块的AI引擎也是包括了三个类,分别负责神经网络结构的Linear_QNet类,负责训练器的QTrainer类,以及负责决策的Agent类。
神经网络的结构仍然是一个全连接的三层神经网络。代码内容和第十三章的内容没有区别,但是注意在实际运行的时候,这里的输入层和隐藏层的神经元参数是不一样的。
class Linear_QNet(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.linear1 = nn.Linear(input_size, hidden_size)
self.linear2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = F.relu(self.linear1(x))
x = self.linear2(x)
return x
def save(self, file_name='model.pth'):
model_folder_path = './model'
if not os.path.exists(model_folder_path):
os.makedirs(model_folder_path)
file_name = os.path.join(model_folder_path, file_name)
torch.save(self.state_dict(), file_name)
训练模块代码和第十三章也没有区别。
class QTrainer:
def __init__(self, lr, gamma,input_dim, hidden_dim, output_dim):
self.gamma = gamma
self.hidden_size = hidden_dim
self.model = Linear_QNet(input_dim, self.hidden_size, output_dim)
self.target_model = Linear_QNet(input_dim, self.hidden_size,output_dim)
self.optimizer = optim.Adam(self.model.parameters(), lr=lr)
self.criterion = nn.MSELoss()
self.copy_model()
def copy_model(self):
self.target_model.load_state_dict(self.model.state_dict())
def train_step(self, state, action, reward, next_state, done):
state = torch.tensor(state, dtype=torch.float)
next_state = torch.tensor(next_state, dtype=torch.float)
action = torch.tensor(action, dtype=torch.long)
action = torch.unsqueeze(action, -1)
reward = torch.tensor(reward, dtype=torch.float)
done = torch.tensor(done, dtype=torch.long)
Q_value = self.model(state).gather(-1, action).squeeze()
Q_value_next = self.target_model(next_state).detach().max(-1)[0]
target = (reward + self.gamma * Q_value_next * (1 - done)).squeeze()
self.optimizer.zero_grad()
loss = self.criterion(Q_value,target)
loss.backward()
self.optimizer.step()
Agent类代码的内容和第十三章也没有区别。
class Agent:
def __init__(self,nS,nA,max_explore=100, gamma = 0.9,
max_memory=5000, lr=0.001, hidden_dim=10):
self.max_explore = max_explore
self.memory = deque(maxlen=max_memory)
self.nS = nS
self.nA = nA
self.n_game = 0
self.trainer = QTrainer(lr, gamma, self.nS, hidden_dim, self.nA)
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
def train_long_memory(self,batch_size):
if len(self.memory)>0:
if len(self.memory) > batch_size:
mini_sample = random.sample(self.memory, batch_size) # list of tuples
mini_sample = self.memory
states, actions, rewards, next_states, dones = zip(*mini_sample)
states = np.array(states)
next_states = np.array(next_states)
self.trainer.train_step(states, actions, rewards, next_states, dones)
def get_action(self, state, n_game, explore=True):
state = torch.tensor(state, dtype=torch.float)
prediction = self.trainer.model(state).detach().numpy().squeeze()
epsilon = self.max_explore - n_game
if explore and random.randint(0, self.max_explore) < epsilon:
prob = np.exp(prediction)/np.exp(prediction).sum()
final_move = np.random.choice(len(prob), p=prob)
else:
final_move = prediction.argmax()
return final_move
完整的代码参看brick_agent.py文件。
三、环境和AI引擎的组装运行
我们已经有了一个游戏环境,有了一个AI引擎Agent。下面需要用一个函数将二者组装在一起进行交互。我们编写一个训练函数train,这个函数内容和第十三章的相应内容基本一致。
在train函数内将Game类和Agent类进行实例化,得到两个对象。通过get_state函数来获取初始状态。之后是游戏主循环,在主循环中将状态信息输入给Agent得到相应的决策信息final_move,将这个决策再输入给环境得到这个决策运行对应的结果,包括奖励等信息。随后再获得新的游戏状态。注意在这里使用了一个函数ball_near_bat来执行一个判断条件,因为打砖块游戏中存在大量无关紧要的帧,例如球在砖块上飞行的时候,此时砖块的移动就和球的飞行没太大关系。所以在重要时候,才需要进行记忆的操作。
def train():
plot_scores = []
plot_mean_scores = []
record = 0
total_step = 0
game = Game()
agent = Agent(game.nS,game.nA)
state_new = game.get_state()
while True:
state_old = state_new
final_move = agent.get_action(state_old,agent.n_game)
reward, done, score = game.play_step(final_move)
state_new = game.get_state()
if game.ball_near_bat():
agent.remember(state_old, final_move, reward, state_new, done)
agent.train_long_memory(batch_size=256)
total_step += 1
if total_step % 10 == 0:
agent.trainer.copy_model()
如果本轮游戏结束,将所有环境数据重置。如果本轮游戏打掉的砖块超过历史最高记录,则更新这个分值记录,同时把模型保存。之后我们把有关的几个数据进行绘图,方便我们监测观察游戏过程中,AI引擎的学习过程。
if done:
game.reset()
agent.n_game += 1
if score > record:
record = score
agent.trainer.model.save()
print('Game', agent.n_game, 'Score', score, 'Record:', record)
plot_scores.append(score)
mean_scores = np.mean(plot_scores[-10:])
plot_mean_scores.append(mean_scores)
plot(plot_scores, plot_mean_scores)
完整的代码可以参考brick_ai.py文件。
最后我们来运行游戏,在终端输入如下命令。
游戏截图显示如下,你会观察到一些有趣的现象。例如在一开始,AI控制的球板不知道如何行动,它处于一种随机移动的状态。当它偶尔能接住球后,游戏会给AI一些正向的反馈。它会越来越明白应该如何根据球的位置来移动球板。
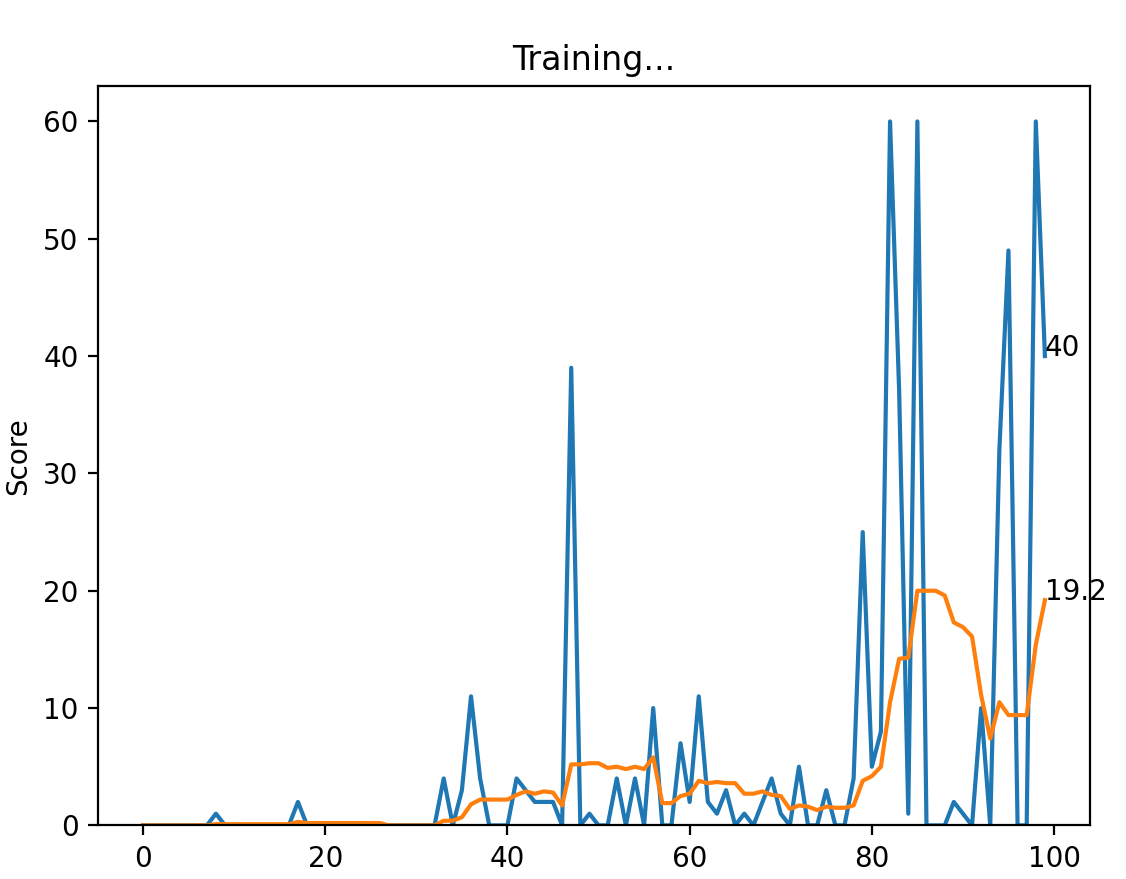
我们可以看看绘图窗口的结果,横轴是我们游戏的轮数,纵轴是每轮游戏得到的分数。这个统计图可以帮我们从全局上监测打砖块AI的学习进度。一开始的时候成绩比较差,到了100轮左右,最高已经可以得到60分,AI的确从环境交互中学习了知识,知道如何处理状态信息,如何来拿到较好的收益。
本章小结:
本章和上一章内容相似,可以让我们重复巩固已经学习到的内容。包括两个方面,一个是学习如何修改人工操作游戏,打造成一个可以和AI相配合的游戏环境。另一个是复用了上一章的代码,来构造了一个打砖块AI引擎。不过本章的代码还是有一些不一样的地方。重要的区别在于AI引擎的输入是不一样的,此处的输入信息只有5个特征,所以神经网络的结构也不一样了。另一个区别在于AI引擎在处理记忆时也不一样,它只会记忆重要的游戏环节。
我们还可以进一步想想,还可以怎么玩?读者可以尝试自己做一些修改。一方面是去尝试修改环境,目前的砖块是静止不动的,如果改成会移动的砖块,AI还会得到高分吗?另一方面,可以去修改AI引擎,目前我们使用了5个特征来计算状态信息,这里面没有考虑到砖块的位置信息。你能否设计一些更有用的状态信息?
下一章,我们将会把第六章笨鸟先飞的游戏环境和AI相结合。我们不仅会使用DQN来驱动小鸟飞行,还会尝试用遗传算法来生成一大群小鸟,是不是很壮观。