第十二章:遗传算法
在前面章节我们已经学习到三种人工智能算法,分别是第八章的人工神经网络,第九章的蒙特卡罗方法,和第十章的强化学习。本章将学习第四种人工智能算法,也就是遗传算法。遗传算法是模拟自然生物界的运行规律,解决最优化问题。我们回忆第八章中的内容,在第八章中可以用梯度下降算法来解决最优化问题,本章将尝试用遗传算法来解决同样的问题,并且尝试用遗传算法来训练神经网络。
一、什么是遗传算法
遗传算法是受到大自然规律的启发,如果一个生物种群要在自然界生存下去,它必须将优秀的个体遗传到下一代。以长颈鹿这个种群为例,因为自然竞争,低处的植物被很多动物吃掉了,为了生存,它们的身高需要越来越高,否则无法吃到高处的食物。上一代的长颈鹿产生下一代时,下一代的身高不会都能够到高处的食物,那些身高不足的下一代必然容易夭折早亡,那些有足够身高的下一代自然容易存活,并给再下一代传续它们的身高基因。
为了后面编程方便,我们需要定义相关的术语。
- 种群:在生态环境中是一群生物,在算法中是一组可能的解。
- 个体:在生态环境中是单个生物,在算法中是一个解。
- 杂交:在生态环境中是两个上一代的生物产生下一代,在算法中是将两个解进行组合,组合的方式会依赖问题而变化。杂交的目的是让两个各有优势的基因能组合到一起。
- 变异:在生态环境中是某个下一代的生物特征产生突变,在算法中是对某个解进行随机变化。变异的目的是探索可能的基因组合,以更好的适应环境。
- 适应度:在生态环境中是生物个体或种群对于环境的存活性,在算法中是对于解的优秀程度的判断。
- 父代和子代:在生态环境中是上一代和下一代,在算法中是迭代的前一次和后一次两组不同的解。
遗传算法解决问题一般来讲会有若干流程步骤: - 对解空间进行编码,也就是将某个问题的可能的解的形式,编写成遗传算法兼容的形式。 - 生成一组解的集合,基于随机方法生成一组初始的解,也称之为初始种群。 - 计算初始种群的适应度,适应度是一种量化指标,用来判断某个解的优良程度。类似于种群个体对于环境的适应程度。 - 选择能进行繁衍的个体,算法根据适应度来选择出那些优良的个体,然后将其作为繁衍后代的候选者。 - 根据选择出的个体进行后代繁衍,这种繁衍出的后代,往往是父代基因的交叉结果,也包含了一定程度的变异。 - 后代繁衍出来后,种群规模膨胀,需要选择哪些个体能存活到下一代。然后新的下一代种群,将成为下一次迭代的父辈。
二、用遗传算法解决最优化问题
从自然界的规律出发,我们可以将二次方函数想像成一个生态环境,只有在低洼处生活的动物才有水喝,才能够生存下来。假设一开始有一群动物,随机分散在二次方函数那座山上,不同高度的动物得到的水不同,越低处水资源越丰富,存活度越高,高处的动物不容易存活,而低处的动物容易存活从而留下它们的基因,低处动物的下一代会更容易往低处走,从而找到山谷的最低点。
为了后面编程方便,我们需要定义相关的术语。
- 种群:二次方函数中是一组可能的解
- 杂交:在二次方函数中是两个解进行加权求合
- 变异:在二次方函数中是某个解进行随机加减
- 适应度:在二次方函数中是解对应的Y轴值,我们希望找到最低点,所以越低越好。
首先我们初始化种群,产生最初的一代,包括10个个体,也就是10个可能的解,分散在-2到+2之间的区间上。
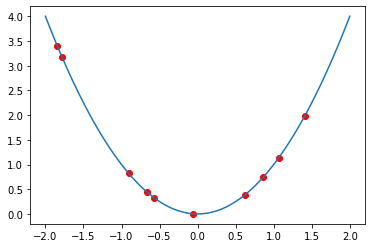
下面我们定义适应度,用于评估个体和种群的质量,因为我们希望找到最低点,所以用二次方函数加负号来表示,这样一来,越在山高处的点,适应度值越小,越在山低处的点,适应度值越大,质量越好。此外,如果对于-2和+2以外的点,设置为一个比较大的负数,以表示适应度很差。
利用前面的函数计算出整体种群的平均适应度和最大适应度。
def fitness_pop(pop):
pop_fit = np.array([fitness(x) for x in pop])
avg_fit = pop_fit.mean()
max_fit = pop_fit.max()
return avg_fit,max_fit
适应度较高的优秀个体更容易存活,并产生下一代。为了体现这一点,我们将适应度转换为一个选择概率,以方便后续抽样的时候使用这个概率。
def fitness_prob(pop):
return np.exp([fitness(x) for x in pop])/np.sum(np.exp([fitness(x) for x in pop]))
fitness_prob(pop)
随后我们来定义交叉函数和变异函数。交叉函数体现了两个个体杂交的思想,具体计算是将两个解进行加权求和。
def crossover(p1,p2):
weight = np.random.rand()
p1_sub = p1*weight
p2_sub = p2*(1-weight)
children = p1_sub+p2_sub
return children
变异函数体现了个体变异的思想,具体计算是对某个解进行随机的加减,相当于对局部周围进行了随机搜索。
下面我们再定义两个算法参数,mut_rate是变异率,也就是在整个种群中,会有多大比例的下一代个体会产生变异。同时定义一个种群大小,变量命名为children_size。
之后来定义繁衍函数,它负责根据父代的种群来产生下一代种群,也称为子代种群。在这个函数中,首先计算种群中个体的适应度,再基于适应度来选择两个个体,用这两个个体进行杂交,也产生下一代。适应度高的优秀个体会有更大机会被抽中,从而产生下一代。循环的次数,控制了产生下一代的数量。
def reproduce(pop_parent,children_size):
next_generation = []
prob = fitness_prob(pop_parent)
for _ in range(children_size):
p1, p2 = np.random.choice(len(pop),size=2, replace=False,p=prob)
next_generation.append(crossover(pop_parent[p1], pop_parent[p2]))
return np.array(next_generation)
def pop_mutate(pop,mut_rate):
mut_num = int(mut_rate*len(pop))
mut_index = np.random.choice(len(pop), mut_num,replace=False)
for i in mut_index:
pop[i] = mutate(pop[i])
return pop
还需要一个选择函数,将父代和子代进行合并操作,让某些优良基因存活到下一代,其它的基因接受死亡的命运。这个函数就是将两个集合进行合并,再使用choice函数进行选择。该函数就起着自然选择的作用。
def selector(pop_parent,pop_children):
pop_group = np.concatenate([pop_children,pop_parent])
prob = fitness_prob(pop_group)
index = np.random.choice(len(pop_group),size = len(pop_parent),replace=False,p=prob)
return pop_group[index]
下面我们看一下最终是如何使用这些函数的。首先产生初代种群,包括了10个个体。然后计算其适应度。用while循环进入种群进化迭代。reproduce函数将父代种群中优秀的个体进行杂交繁衍。产生下一代。再对其中的部分个体进行变异。然后选择出进化到下一代的种群next_generation。再计算新一代种群的适应度。最后将next_generation赋值成父代种群,进入新一轮进化。
pop_parent = init_pop(10)
avg_fit, max_fit = fitness_pop(pop_parent)
iter_num = 0
while iter_num < 10:
next_generation = reproduce(pop_parent,children_size)
next_generation = pop_mutate(next_generation,mut_rate)
next_generation = selector(pop_parent,next_generation)
avg_fit, max_fit = fitness_pop(next_generation)
print("第{n}代种群的适应度:{x:.3f},最优秀的适应度:{y:.3f}".format(n=iter_num, x=avg_fit,y=max_fit))
iter_num = iter_num + 1
pop_parent = next_generation
第0代种群的适应度:-0.402,最优秀的适应度:-0.000
第1代种群的适应度:-0.193,最优秀的适应度:-0.000
第2代种群的适应度:-0.063,最优秀的适应度:-0.006
第3代种群的适应度:-0.026,最优秀的适应度:-0.001
第4代种群的适应度:-0.019,最优秀的适应度:-0.001
第5代种群的适应度:-0.010,最优秀的适应度:-0.000
第6代种群的适应度:-0.023,最优秀的适应度:-0.000
第7代种群的适应度:-0.023,最优秀的适应度:-0.001
第8代种群的适应度:-0.009,最优秀的适应度:-0.000
第9代种群的适应度:-0.009,最优秀的适应度:-0.000
从结果可以看到,进行了十轮迭代之后,种群平均适应度已经接近于0,也就是种群中所有个体都已经到达山谷最底部。
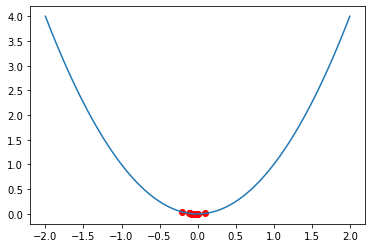
三、用遗传算法解决背包问题
前面的问题相对比较简单,我们再来看一个略有难度的问题,即经典的背包问题。假设我们有一个背包,最大容量是150公斤。我们有七件物品可以选择要不要放入背包中,这些物品的价值和重量分别如下。我们要做的是选择一个物品集合,让这个物品集合的价值最大,但是重量不能超过背包承受能力。
可以理解,背包问题是一个有约束的最优化问题。约束是背包的承受能力,最优化目标是放入背包中的物品价值之和。我们依然可以使用遗传算法来解决这个问题。首先还是产生一初始种群。因为问题有点不一样了,所以解的形式也不一样,这里我们用一组0或1的数字来表示个体或基因。init_pop函数包括两个参数,pop_num表示种群中个体数量,pop_size表示个体中0或1的数字个数,这串数字的长度和物品集合有关。用这个函数产生20个个体,每个个体中的基因是一串数字,因为物品全集有7个,所以数字长度为7。你可以把这个基因看作是一个有七个数字元素的列表或向量。
def init_pop(pop_num,pop_size):
pop = []
for _ in range(pop_num):
pop.append(np.random.randint(0,2,pop_size))
return np.array(pop)
pop = init_pop(20,7)
def fitness(select):
result = np.sum(select*value/weight)
sum_weight = np.sum(select*weight)
if sum_weight > 150:
result = -100
return result
def fitness_pop(pop):
pop_fit = np.array([fitness(x) for x in pop])
avg_fit = pop_fit.mean()
max_fit = pop_fit.max()
return avg_fit,max_fit
基于适应度函数计算选择概率的函数,和之前差别不大。
def fitness_prob(pop):
return np.exp([fitness(x) for x in pop])/np.sum(np.exp([fitness(x) for x in pop]))
由于个体的表现形式是一串0或1的数字,所以交叉函数也不一样,这里我们将两组数字进行随机拼接来产生新的解。crossover函数中输入两个个体,随机选择一个拼接位置,将两个个体的基因进行截断并进行拼接。
def crossover(p1,p2):
index = random.randint(1,len(p1))
p1_sub = p1[:index]
p2_sub = p2[index:]
children = np.concatenate([p1_sub,p2_sub])
return children
mutate是个体变异函数,它是将基因向量中某个数字随机转换成0或是1。
def mutate(select):
index = np.random.choice(len(select), 1)
if select[index] ==0:
select[index]=1
else:
select[index]=0
return select
整体的代码逻辑和前面的代码基本一致,仍然是产生初代种群,然后计算适应度。在循环中根据适应度来顺序进行三种函数操作。
pop_parent = init_pop(20,7)
avg_fit, max_fit = fitness_pop(pop_parent)
iter_num = 0
while iter_num < 20:
next_generation = reproduce(pop_parent,children_size)
next_generation = pop_mutate(next_generation,mut_rate)
next_generation= selector(pop_parent,next_generation)
avg_fit, max_fit = fitness_pop(next_generation)
print("第{n}代种群的适应度:{x:.3f},最优秀的适应度:{y:.3f}".format(n=iter_num, x=avg_fit,y=max_fit))
iter_num = iter_num + 1
pop_parent = next_generation
def total_value_weight(pop):
total_value = np.sum([s*value for s in pop],1)
total_weight =np.sum([s*weight for s in pop],1)
return total_value, total_weight
total_value_weight(pop_parent)
所以从上述两个例子可以看到,遗传算法可以解决不同类型的最优化问题。其基本逻辑都是根据杂交和变异来解决的,只是需要根据问题不同,来编写不同的杂交和变异函数。
四、用遗传算法来训练神经网络
既然遗传算法可以用来解决最优化问题,那自然也能用来训练神经网络了。我们会用第八章矩形面积的例子来介绍如何编写代码。
首先人工生成100个不同的矩形,X表示将要输入神经网络的矩形边长,y表示需要神经网络去预测的矩形面积。
随后我们来定义一些超参数,例如神经网络的输入层、隐藏层、输出层节点个数。迭代次数n_iter,种群中个体数量generation_size,变异比例mutate_rate。以及神经网络总参数量parameter_len。
input_size = 2
hidden_size = 50
output_size = 1
n_iter = 3000
generation_size = 20
mutate_rate = 0.2
parameter_len = (input_size+1)*hidden_size+(hidden_size+1)*output_size
criterion = nn.MSELoss()
我们需要找到最优秀的那个神经网络,所以种群的每个个体都是一个神经网络类,也就是NeuralNet类,它的定义和第八章类似,只不过有两个新增函数。我们的神经网络是继承的pytorch中的Module类,网络中的权重参数看作是个体的基因。那为了后续的交叉和变异计算,需要两个函数,方便获取和设置神经网络的参数。get_weight函数用于获取神经网络的权重参数。set_weight函数用于设置神经网络的权重参数。
class NeuralNet(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.linear1 = nn.Linear(input_size, hidden_size)
self.linear2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = F.relu(self.linear1(x))
x = self.linear2(x)
return x
def get_weight(self):
return deepcopy([self.linear1.weight.data,
self.linear1.bias.data,
self.linear2.weight.data,
self.linear2.bias.data])
def set_weight(self,weights):
weights = deepcopy(weights)
self.linear1.weight = nn.Parameter(weights[0])
self.linear1.bias = nn.Parameter(weights[1])
self.linear2.weight = nn.Parameter(weights[2])
self.linear2.bias = nn.Parameter(weights[3])
init_pop函数用于产生初代种群,函数代码很简单,就是基于for循环往pop列表中存放多个NeuralNet类。
def init_pop(size = generation_size):
pop = []
for _ in range(size):
pop.append(NeuralNet(input_size, hidden_size, output_size))
return pop
随后是适应度计算函数,一个神经网络是否适应环境当然是要看它的损失是多少了。fitness函数中计算神经网络的预测值,再计算其和标签的损失值,因为损失是越小越好,而适应度是越大越好,所以要把损失当作适应度需要有一个倒数操作。
fitness_prob是计算种群的适应度,用循环来遍历所有的个体,计算个体适应度后,计算其相对值。这样就可以当作概率来使用。
def fitness(model,inputs, targets):
outputs = model(inputs)
loss = criterion(outputs, targets)
output = 1/loss.item()
return output
def fitness_prob(pop,inputs, targets):
fitness_value = []
for model in pop:
fitness_value.append(fitness(model, inputs, targets))
fitness_value = np.array(fitness_value)
return fitness_value/np.sum(fitness_value)
get_pop_weights函数用一个循环来获取种群中所有个体的参数。set_pop_weights函数也是用来设置种群中所有个体的参数。
def get_pop_weights(pop):
weights = []
for model in pop:
weights.append(model.get_weight())
return weights
def set_pop_weights(pop, weights):
for model, weight in zip(pop, weights):
model.set_weight(weight)
return pop
因为我们使用的神经网络有三层,共四组权重参数,其数据格式是pytorch中的嵌套tensor格式,为了方便处理,定义两个辅助函数。list2tensor函数用于将这四组参数进行拼接,形成一个长串的向量。tensor2list函数则相反的操作,将一个长串的向量,切分成四组参数。
def list2tensor(weights):
return torch.concat([weights[0].flatten(),weights[1],
weights[2].flatten(),weights[3]])
def tensor2list(weights):
output_weights = []
index = [input_size*hidden_size,
input_size*hidden_size+hidden_size,
input_size*hidden_size+hidden_size+hidden_size*output_size]
output_weights.append(weights[:index[0]].reshape(hidden_size,input_size))
output_weights.append(weights[index[0]:index[1]])
output_weights.append(weights[index[1]:index[2]].reshape(output_size,hidden_size))
output_weights.append(weights[index[2]:])
return output_weights
cross_mutate函数就是核心处理交叉和变异的功能。输入参数是两个神经网络的参数,以及参数变异比例rate。将这两个神经网络参数进行处理后,变成长串的参数列表,选择随机位置进行拼接。这里的拼接逻辑和背包问题的思路是一致的。再进入变异流程,不需要所有的个体都参与变异,种群大小和变异参数相乘,得到需要变异的个体数量。也就是说当生成的随机数小于这个乘积时,才需要进行变异流程。从整体上可以让大约20%的个体进入变异。
本例中神经网络中包括了数百个参数,具体数值可以看parameter_len的大小。我们只需要修改其中部分参数数值,所以会进入一个循环,将部分参数值增加一个随机噪声。
def cross_mutate(weights_1, weights_2, rate):
weights_1 = list2tensor(weights_1)
weights_2 = list2tensor(weights_2)
crossover_idx = random.randint(0, parameter_len-1)
new_weights = torch.concat([weights_1[:crossover_idx] , weights_2[crossover_idx:]])
if random.randint(0,generation_size-1) <= generation_size*mutate_rate:
mutate_num = int(rate*parameter_len)
for _ in range(mutate_num):
i = random.randint(0,parameter_len-1)
new_weights[i] += torch.randn(1).numpy()
output_weights = tensor2list(new_weights)
return output_weights
然后将上面一些核心函数组装起来,构成繁衍函数reproduce。它的输入参数是种群,数据输入和数据标签。它会构造一个空列表,计算种群适应度概率,排序后选择两个最优秀的神经网络。这两个个体直接进入下一代。这种思路称为精英方法,是为了让优秀的个体直接保留下来,增加稳定性。剩下的席位,就会通过优选杂交来产生。选择的概率和个体适应度有关。
def reproduce(pop,inputs, targets):
next_generation = []
weights = get_pop_weights(pop)
prob = fitness_prob(pop,inputs, targets)
second_index, first_index = list(np.argsort(prob)[-2:])
next_generation.append(weights[first_index])
next_generation.append(weights[second_index])
for _ in range(generation_size-2):
p1, p2 = np.random.choice(len(prob),size=2, replace=False,p=prob)
next_generation.append(cross_mutate(weights[p1],weights[p2],rate=0.01))
return next_generation
最后我们调用上述编写好的函数,初始化种群,产生20个神经网络。在迭代循环中,产生新一代的神经网络参数,将这些参数进行权重设置。每过100个迭代,观察一下最优秀的模型的效果,观察其损失大小。
model_pop = init_pop()
inputs = torch.from_numpy(X).to(torch.float)
targets = torch.from_numpy(y).to(torch.long)
for epoch in range(n_iter):
next_generation = reproduce(model_pop,inputs, targets)
set_pop_weights(model_pop, next_generation)
if (epoch>0 and epoch%100==0):
with torch.no_grad():
best_model = model_pop[0]
outputs = best_model(inputs)
loss = criterion(outputs, targets)
print ('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, n_iter, loss.item()))
Epoch [101/3000], Loss: 93.9174
Epoch [201/3000], Loss: 17.6046
...
Epoch [2801/3000], Loss: 0.4593
Epoch [2901/3000], Loss: 0.4478
可以看到损失函数的值能顺利往下降,说明神经网络的训练是成功的。
我们也可以取出训练好的神经网络,让它计算一个矩形面积,看是否正确。
本章小结
本章我们学习了第四种人工智能算法,遗传算法。它利用自然选择的思路,来解决一个最优化问题。使用遗传算法需要根据不同的实际问题灵活应用。首先将问题的解转换成基因编码,然后将问题的目标转换成环境的适应度。并考虑交叉和变异函数的代码实现问题。
我们使用遗传算法解决了背包问题和训练神经网络的问题。大家可以自行尝试用遗传算法来处理第八章中的井字棋数据。看你是否可以得到和梯度下降类似的结果。
到本章为止,我们已经学完了四种人工智能算法。本书的后续内容,我们会将这些算法应用到游戏环境中。我们将在第十五章来应用遗传算法,具体来讲我们会使用遗传算法来玩笨鸟先飞的游戏。我们会一次生成一大群鸟,一起来通过可怕的钢管丛林。如果你来设计,你会如何将这两个部分进行整合呢?而在下一章,我们会把贪吃蛇游戏环境和深度强化学习进行结合。让我们赶紧开始玩吧。