第十章:强化学习入门
本章我们会学习人工智能领域的一个重要方法,强化学习。从强化学习的名字可以理解,其主要思路是利用奖惩,来强化或矫正某些行为。我们将通过一些例子来深入理解强化学习的算法。并且研究一个迷宫环境,构建不同的强化学习算法来通关这个迷宫。
一、什么是强化学习
我们在生活中也会不自觉的用强化学习的思想。例如我们刚刚抱养了一只小狗,希望能训练它按照人的指令行动,因为小狗听不懂人的语言,所以没法上课教育它,但是可以对它的行动进行强化或矫正。如果我们让它坐下,它做出了对的行为,我们就奖励给它一根肉骨头,如果它做出了错的行为,我们就不给骨头或者给一个小小的惩罚。很快它就能明白应该怎么去做了。当我们上学的时候,一个学期结束,如果表现的很好,老师可能会根据表现发给我们一朵小红花。如果表现的糟糕,老师可能会去家访,我们可能就会挨揍,这也是强化学习。
强化学习看起来和第八章学习的有监督学习有点像。二者都有一种监督机制和反馈机制。重要的区别在于,有监督学习对每一个行为或者每一条数据都需要对应的标签。但是在强化学习的应用的场景中,在一系列的行为完成后才会得到反馈。这种延迟的反馈在生活中也会遇到,比方说,我们今天努力的读书学习,这个动作今天可能并不会马上有正面的反馈,但是期终考试或是未来的什么时候,今天的努力会得到正面的反馈。所以强化学习的应用场景是在没有丰富的即时的标签,但是又可以获得少量延时反馈的情况下的。
让我们设想一个具体的计算机应用场景。我们需要给一个机器人编写程序,让它能通过一个迷宫,迷宫中有的地方是墙壁,有的地方是陷阱,有的地方是迷宫出口。机器人并不清楚整个迷宫的情况,每次它可以选择往四个方向中的任一个方向走一步,它每走完一步,并不会立刻得到反馈信息,要等到它最终找到出口或掉入陷阱后,才会有反馈。那么问题是我们应该如何编写程序,让它能根据这种反馈,最终能找到出口,而且避免落入那些陷阱呢?
之前学到的有监督学习并不适用于这个问题,因为有监督学习需要在每一步之后都要对应一个反馈,但是该问题中机器人并不能马上得到反馈,它只能在走到特定的地方才能得到反馈。直觉上应该怎么解决这个问题呢?其实还是依靠试错、反思和记忆。机器人一开始可以随机的探索这个未知的迷宫世界,当它走到出口的地方时候,它会明白之前的一系列努力是有用的,当它走到有陷阱的地方时候,也会明白之前那些行为可能是有问题,需要回避的。下次再遇到类似的状况就不会再采用有问题的行为。
所以强化学习本质上就是试错、反思和记忆,下面我们将直觉上的这些东西用一些正式的概念进行表达。
- 主体(agent):谁来负责做出行动,谁来承受后果,也就是进行试错学习的主体。本例中就是机器人。
- 环境(environment):对主体的行动作出反馈,本例中就是迷宫。
- 动作(action):主体可以选择的行动有哪些,本例中的动作就是上下左右这四个动作,以决定行进的方向。
- 状态(state):主体的一系列状况。本例中就是机器人在迷宫的位置坐标。
- 策略 (strategy):主体的应对方案,是从输入状态,到输出动作的一个函数。本例中就是机器人如何走迷宫的方案。
- 回报(reward):主体在环境中进行了某些动作之后得到的奖惩,本例中就是找到出口得到正的回报,或是落入陷阱得到负的回报。
我们通过下面这个图来具体解释一下强化学习的几个概念的关系。这个图表达的是一种主体和环境交互的关系,主体身处于环境之中,它的目标是要让自己的回报最大,也就是能快速走出迷宫。它可以从迷宫环境得到一些信息,这些信息主要包括两部分,一部分是主体在环境中的状态信息,具体而言就是位置坐标,另一部分是环境给主体的回报,只有当主体到达迷宫出口的时候才会有正回报。主体拿到这两部分信息后需要根据自己的策略来返回一个动作,这里就是走迷宫的四个方向选择其一。主体将动作进行实行执行,环境得到主体的动作之后,给出下一步的状态和回报信息。以此不断循环迭代。
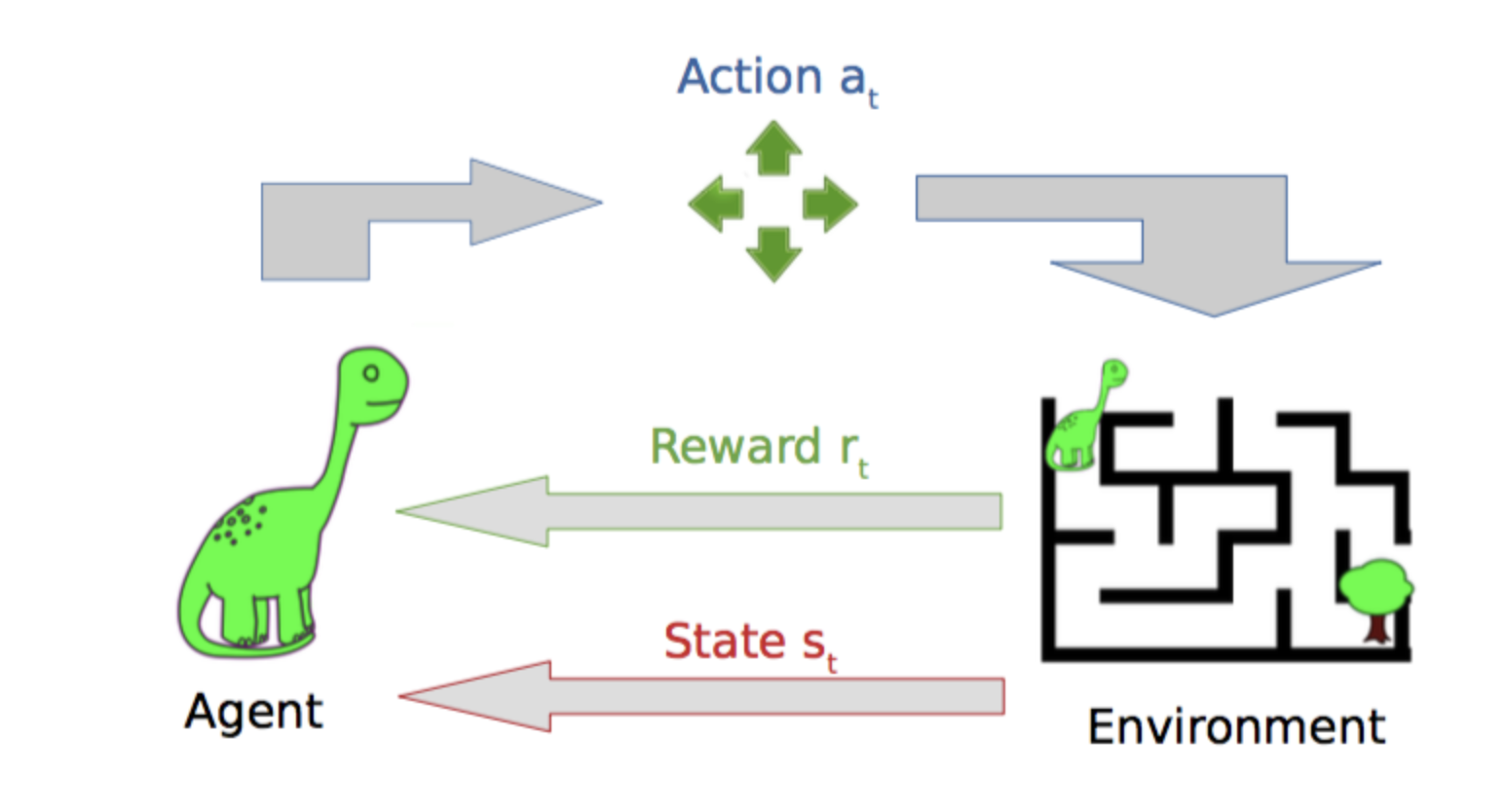
总而言之,强化学习就是要训练主体,通过自己走迷宫,和环境进行交互,再根据一系列动作后的回报,来找到走迷宫的策略。
二、冰湖问题
下面我们来解决一个更具体的迷宫问题,就能够清晰的理解前面说的那些概念了。如下图所示,这是一个名叫冰湖的小迷宫。

这个迷宫有4乘4的大小,一共有16个格子位置。主体是一个机器人,它的初始位置是在左上角的位置,机器人可以往四个方向行走,但无法走出这16个格子以外的地方。如果在初始位置还要试图向左行走,它将停留在原地,因为16个格子的外面四周都是墙壁。如果能顺利的走到右下角的出口位置,则可以获得一份礼物奖励并结束本轮冒险游戏。需要注意到冰湖中有四个位置是陷阱,例如走到第二排第二列的格子位置上时,就会掉入这个湖上的洞里去,这样也结束本轮冒险,但不会有任何奖励或惩罚。最后还需要注意一点的是,冰湖上很滑而且有风,所以机器人行走时,其下一步的结果并不是确定性的,而是存在随机性。例如机器人的动作是往右走一步,但是真正能往右走一步的概率是1/3,另外有1/3的概率会向上走一步,有1/3的概率会向下走一步。这是环境的随机性造成的。
- 主体(agent):本例中是处于迷宫中的机器人。
- 环境(environment):本例中环境就是16个格子的迷宫。
- 动作(action):本例中动作就是上下左右这四个动作,以决定行进的方向。在代码中会有四个数字代表方向,0代表向左,1代表向下,2代表向右,3代表向上。
- 状态(state):本例中就是机器人在冰湖迷宫中的位置坐标。因为是有16个格子,所以用数字0到15来表示从左到右,从上到下顺序的位置。数字0是左上角位置,数字15是右下角位置。四个陷阱的位置分别是5,7,11,12。
- 策略 (strategy):本例中就是机器人如何走冰湖迷宫的方案,这个方案就是一个函数,它的输入是位置坐标,输出是四种方向动作。
- 回报(reward):本例中到达15的状态则回报+1,在其它位置时回报为0。
在python中有一个gym模块,它提供了强化学习所必需的环境对象。其中就内置了这个冰湖迷宫。我们用下面的代码来加载模块,并使用这个迷宫环境。
env是一个可以调用的环境对象。我们可以在代码中来和环境交互。reset是将环境重置,此时会将agent放在左上角出生点,并返回其状态值state等于0。之后可以用render函数将环境显示在窗口中。step函数是我们和环境交互的函数,函数输入参数是动作action,此时输入2表示向右方行走。
其函数返回值将有五个,存放在一个元组中。我们主要关注前三个即可,分别表示输入2的行动后,机器人所处的新state是什么,获得的reward是多少,本轮游戏有没有结束。 新的state等于1,表示现在处于初始位置右侧的格子里。获得的reward等于0,此时没有得到任何回报。第三个元素False表示游戏还没有结束。在最后不需要交互了,可以用close来关闭这个游戏环境。
下面我们用这个环境来尝试一些简单的交互。为了更好的显示观察我们的策略及其效果,我们先定义两个辅助函数。
print_policy函数是为了显示出当前的策略。所谓策略是指一套完整的应对逻辑,当我们处于什么状态时,就进行什么样的动作。也可以认为策略就是一个从state到action的函数。在print_policy这个函数的输入参数中,pi就是策略函数。这个函数中的主体是一个for循环,遍历了所有的迷宫状态,输入给策略函数,得到对应的行动方向a,将这些信息打印输出,方便我们观察策略函数的内在逻辑。
def print_policy(pi, env, n_cols=4):
print('Policy:')
arrs = {k:v for k,v in enumerate(('<', 'v', '>', '^'))}
nS = env.observation_space.n
for s in range(nS):
a = pi(s)
print("| ", end="")
if s in [5,7,11,12,15]:
print("".rjust(9), end=" ")
else:
print(str(s).zfill(2), arrs[a].rjust(6), end=" ")
if (s + 1) % n_cols == 0: print("|")
test_game函数是用于测试策略函数的效果。核心部分是一个for循环,每次循环中重启新环境,用策略pi来输入初始state,得到行动action,反复和环境交互。得到新的状态和回报,以及是否结束的标志。这种交互直到游戏结束。游戏结束就是while循环的结束,此时判断最终得到的reward是否大于0,并将结果存入results列表中,如果我们能走到冰湖右下角,reward才会大于0,所以它会计算在100轮走迷宫游戏中,给定使用某个策略,能有多少比例成功通关。
def test_game(env, pi):
results = []
for _ in range(100):
state,_ = env.reset()
Done = False
while not Done:
action = pi(state)
state, reward, Done, _ ,_= env.step(action)
results.append(reward>0)
return np.sum(results)/len(results)
一开始我们也不知道应该怎么确定走迷宫的策略,但是没关系,我们先想想第九章的随机模拟思想。先胡乱走一下,总比什么都不做强,所以我们先生成一个随机的策略,来看看表现怎么样。这个随机乱走的策略是用choice函数从四个方向中随机选择。所谓随机策略是指策略的生成是随机的,当策略遇到同一个状态时,它给出的动作方向是确定而非随机的。
生成的随机策略我们保存为random_pi函数,它本质上是一个字典。然后调用上述的两个辅助函数,先打印显示这个策略的逻辑,方便我们观察。随后测试这个策略,走迷宫一百次看能有多少次成功通关。
env = gym.make('FrozenLake-v1')
env.reset()
random_pi = lambda s: {k:v for k in range(16) for v in np.random.choice(4,16)}[s]
print_policy(random_pi,env)
print('Reaches goal {:.2f}%. '.format(
test_game(env, random_pi)*100))
Policy:
| 00 < | 01 ^ | 02 v | 03 ^ |
| 04 v | | 06 ^ | |
| 08 > | 09 v | 10 v | |
| | 13 > | 14 v | 15 |
Reaches goal 0.00%.
这个随机的策略是胡乱行动的,丝毫没有考虑当前的状态情况,所以表现效果很差,没有一次能通关成功,全部掉入陷阱之中了。
那怎么办呢?让我们启用一下人脑智能吧,把眼睛瞪大了,看看这个迷宫的结构。是不是只要能绕过陷阱,往右下方向走就可以呢?我们来制定一个人工经验下的策略函数吧。这个函数称为human_pi,它刻意的回避了陷阱方向。这个策略已经利用了我们的上帝之眼,算是开挂了。
LEFT, DOWN, RIGHT, UP = range(4)
human_pi = lambda s: {
0:RIGHT, 1:RIGHT, 2:DOWN, 3:LEFT,
4:DOWN, 5:LEFT, 6:DOWN, 7:LEFT,
8:RIGHT, 9:RIGHT, 10:DOWN, 11:LEFT,
12:LEFT, 13:RIGHT, 14:RIGHT, 15:LEFT
}[s]
print_policy(human_pi, env)
print('Reaches goal {:.2f}%. '.format(
test_game(env, human_pi)*100))
Policy:
| 00 > | 01 > | 02 v | 03 < |
| 04 v | | 06 v | |
| 08 > | 09 > | 10 v | |
| | 13 > | 14 > | 15 |
Reaches goal 6.00%.
看看我们的人脑智能定的策略,从方向上看,我们都避免走向陷阱的方向,而且也是往右下角的正确方向行走的,尽管如此,我们的成功率也只有6%而已。这是因为,环境里包含有随机性,例如在状态10的位置,human_pi的策略是直接往下走,但有1/3的机会滑到右侧的陷阱中去。那能否制定一个更优秀更安全的策略呢?你可以思考一下。下面我们用强化学习来试试看吧。
三、蒙特卡罗方法解决冰湖问题
让我们回忆一下第九章的知识。在走井字棋的例子中,利用随机走子能评估出某个位置的好坏,那么我们在迷宫中随机走,应该也能评估出在某个状态下进行某种行动的好坏。这个概念就称之为Q值。Q值是计算不同的状态和行动组合下的价值,状态和行动的组合又称之为状态行动对,我们可以用(state,action)这个元组的形式来表达。状态行动对的价值就是Q值,表示为Q(state, action)。例如Q(10,1)就是指当状态位置等于10的时候,选择向下行走时的Q值。
一开始的时候我们不知道怎么算Q值,可以用随机策略大量实验收集数据。例如当遇到位置10就往下方向移动时,它的长期收益是多少,也就是最终通关成功率会是多少。这就是Q(10,1)。那自然我们也会得到Q(10,0),也就是当遇到位置10就往左方向移动的通关成功率。在数据收集完之后,我们可以对比Q(10,1)和Q(10,0),如果向左走更安全更有可能通关,那么Q(10,0)就会大于Q(10,1)。在后续走迷宫时,就可以选择Q值更大的方向。
下面我们开编写相应的代码,基本的代码逻辑如下。
- 步骤1,首先用随机策略在冰湖中行动,通过和环境交互来收集每轮游戏的数据。
- 步骤2,计算每个状态行动对的Q值。也就是Q(state, action)。计算方法是累计从当前一对(state, action)开始后的所有回报,这个累计回报称为G值。多轮游戏就会有多个G,计算它们的平均值,就得到了Q值。所有状态动作组合都能算出对应Q值,它统称为Q表。从步骤1到步骤2,计算Q表的过程称为策略评估。
- 步骤3,再基于Q值来修改优化初始的随机策略。这个过程称为策略优化。
- 步骤4,用另一个环境实验来检验这个优化后的策略效果。
- 步骤5,用优化后的策略再来进行游戏,收集数据,重新计算Q值。
下面就是具体代码了,首先是定义一下select_action函数,它是基于Q值来产生动作。注意这个函数有三个条件分支,如果是纯随机探索,那么mode为explore,此时就只需要在所有的可能的action中随机取值即可,也就是乱走。如果mode为exploit,也就是说Q值已经算的很好了,我们有了一个优化后的策略,直接根据优化后策略行动即可。另外就是一半一半的机会来行动。后续我们会知道这个函数是如何作用的。
def select_action(state, Q, mode):
if mode == "explore":
return np.random.randint(len(Q[state]))
if mode == "exploit":
return np.argmax(Q[state])
if mode == "both":
if np.random.random() > 0.5:
return np.argmax(Q[state])
else:
return np.random.randint(len(Q[state]))
然后我们还需要一个play_game函数来和游戏环境交互,也就是基于策略函数玩一轮游戏,以收集数据。这个函数和test_game函数有点类似,都是使用env.step来和环境交互,直到游戏结束。重要的区别是使用了select_action函数,用随机的方式来产生action,以产生随机探索的效果。还有一点重要的是将每一步action前后的state,以及相关信息一共四个元素,保存在experience中,以方便后续的计算。experience中是单步决策相关的信息,一轮游戏中将所有决策信息都保存在episode中,它用一个numpy的array格式来保存。函数还设置了一个最大步数max_step,以避免一轮游戏交互太长时间。
def play_game(env, Q ,max_steps=200):
state, _ = env.reset()
episode = []
finished = False
step = 0
while not finished:
action = select_action(state, Q, mode='explore')
next_state, reward, finished, _, _ = env.step(action)
experience = (state, action, finished,reward)
episode.append(experience)
if step >= max_steps:
break
state = next_state
step += 1
return np.array(episode,dtype=object)
然后我们来定义最核心的monte_carlo函数。为了计算保存Q表,所以需要定义一个空的Q矩阵。矩阵中每一个元素就代表了给定某个state和某个action下的Q值。一共有16个状态和4个行动,所以Q矩阵的大小就是16乘以4,这个矩阵就是Q表。决策时只需要查询Q表就可以得到动作,所以这里Q表就代表了策略函数。然后我们就开始用for循环来反复游戏,收集数据。也就是步骤1的任务,收集数据的功能就是由play_game函数来负责,这个函数返回的episode就是一轮游戏包含的所有信息。
随后来遍历这一轮游戏收集到的数据,一轮游戏可能包含了若干步信息。通过内层的for循环来遍历每一步信息,取出每一步的state和action,构成一个元组。visited矩阵用来判断某组状态动作对有没有遇到过,如果在本轮游戏中,某一对状态行动是第一次遇到,我们就来汇总信息。汇总方法就是计算G的方法,这里reward是出现这一对状态行动之后的所有回报。discount是折现系数,折现的意义是指时间越久远的价值相对越低,就像是十年后的一块钱,其价值是低于当前的一块钱的。在某一轮游戏信息计算后,我们会得到几个状态行动对的G值。因为我们会重复玩很多轮游戏,所以会用一个字典returns来将这些G值一起保存。然后是用returns中保存的信息来更新Q表,就是简单的平均值计算。得到每对状态行动组合的平均收益。这样就完成了步骤2的任务。也就完成了策略评估的过程。
Q表原本是全零的,现在已经填充了计算好的Q值,更新后的Q表可以用来构造一个策略函数,这就是步骤3的任务,Q值代表了各状态动作组合的价值或通关率,那么只需要选择给定状态下的最大Q值的action即可。这就是策略优化的过程,从开始的随机策略修正到更好的策略。
当实验进行了一定次数后,可以用test_game来观察效果,就是步骤4的测试任务。
def monte_carlo(env, episodes=10000, test_policy_freq=1000):
nS, nA = env.observation_space.n, env.action_space.n
Q = np.zeros((nS, nA), dtype=np.float64)
returns = {}
for i in range(episodes):
episode = play_game(env, Q) # step 1
visited = np.zeros((nS, nA), dtype=bool)
for t, (state, action, _, _) in enumerate(episode):
state_action = (state, action)
if not visited[state][action]:
visited[state][action] = True
discount = np.array([0.9**i for i in range(len(episode[t:]))])
reward = episode[t:, -1]
G = np.sum( discount * reward)
if returns.get(state_action):
returns[state_action].append(G)
else:
returns[state_action] = [G]
# step 2
Q[state][action] = sum(returns[state_action]) / len(returns[state_action])
# step 3
pi = lambda s: {s:a for s, a in enumerate(np.argmax(Q, axis=1))}[s]
if i % test_policy_freq == 0:
print("Test episode {} Reaches goal {:.2f}%. ".format
(i, test_game(env, pi)*100)) # step 4
return pi,Q
到此为止,代码核心部分已经差不多了,我们来实际运行这个函数看看怎么样。
然后我们观察一下最终效果,可以看到效果比人脑智能的策略相比,有不少的提升。达到了23%。
Policy:
| 00 > | 01 ^ | 02 > | 03 ^ |
| 04 < | | 06 > | |
| 08 ^ | 09 > | 10 < | |
| | 13 v | 14 v | |
Reaches goal 23.00%.
不过细心的读者应该会发现,当前的代码还少了步骤5,也就是将优化后的策略来游戏并收集数据。目前优化后的策略只是用来测试了,而用来收集数据用的策略仍然是随机策略,策略评估和策略优化是一个相互促进的过程。用来收集数据用的策略也同样需要使用优化策略。所以需要把play_game函数中的select_action函数参数修改,mode='both'。这样,优化后的策略也有机会用于真正的游戏交互,用于收集更好的数据。这样跑出来算法效果更稳定更优秀。
Policy:
| 00 v | 01 ^ | 02 > | 03 ^ |
| 04 < | | 06 < | |
| 08 ^ | 09 v | 10 < | |
| | 13 > | 14 v | |
Reaches goal 44.00%.
观察一下最终计算出来的策略,这个策略看起来相当的谨慎,在位置10这个地方,它会向左走,而并非直接向下走,避免了落入陷阱的可能。而且最后计算的成功率达到了44%,比人脑智能策略高出很多。
最后归纳一下,强化学习中的蒙特卡罗方法,其初始策略是一个随机策略,通过随机行走玩多轮迷宫收集数据,基于经验数据计算Q表,这个收集数据、计算Q表的过程就是策略评估。然后基于Q表来优化其初始策略,这就是策略优化。策略评估和策略优化的轮流迭代就是强化学习中的蒙特卡罗方法。
四、SARSA算法
上一小节中蒙特卡洛方法的迭代是两大步骤轮流进行的,即策略评估和策略优化,策略评估是给定某个初始策略,评估它在环境中的效果,收集其相关数据。策略优化是根据收集的数据来计算更新Q表里的Q值,并更新策略PI,策略PI再去用于策略评估。蒙特卡洛方法的一个缺点就是要等待,策略评估的核心步骤是计算更新Q表,它需要等到一轮游戏交互完成之后,才能更新Q表以及后面的策略优化。这样会比较慢,而且一整轮游戏的随机性大,算法的波动性很高,结果不稳定。
想像我们有一间房子,我们需要估计这间房子的价值,一种思路就是根据这间房子在未来期限内收到的房租累计求和。因为未来的钱不如现在的钱值钱,所以还需要算一个折现值,这种思路需要我们等待很长时间,把房租都收齐才可以计算。 $$ 当前估计的房价 = 折现系数第一天收到的房租 + 折现系数第二天收到的房租 + 折现系数第N天收到的房租 $$ 另一种思路类似于递归的思路,每天我们用一个算法来估计某一天的房价,到第二天,得到前一天收到的房租,和第二天的估计地价。 这三个数字之间应该存在一个约等的关系。 $$ 当前估计的房价 = 第一天收到的房租 + 折现系数第二天估计的房价 $$ 类似的,当前的状态行动Q值,也近似的等于,产生的收益加上下一步的状态行动Q值。 $$ 当前Q(S,A) = Reward + 折现系数 * 下一步Q(S,A) $$ 所以我们可以得到SARSA算法的核心逻辑,它不需要等待一轮游戏交互完成,而是每一步交互完成后就能进行迭代计算,Q表的更新可以更快更稳定。
使用SARSA算法可以用之前的select_action函数,不过我们来看一种新的思路,就是用choice来实现。它是基于Q值来选择行动,Q值越大越容易被选择中,所以它混合了最优策略和随机策略。函数中Qvalue值是给定某个状态下的所有动作对应的Q值,将它和最大值相减,目的是缩小值域,让后面的exp不会计算溢出。然后再计算出一个相对比率probs。这个值就类似于一个概率值。意思就是某个动作对应的Q值越大,probs越大,越容易被随机选中。
def select_action(state, Q):
Qvalue = Q[state]
norm_Q = Qvalue - np.max(Qvalue)
exp_Q = np.exp(norm_Q)
probs = exp_Q / np.sum(exp_Q)
return np.random.choice(len(Qvalue), p=probs)
下面来看核心代码部分。这里不需要play_game,因为不需要收集整整一轮数据,而是运行单步游戏,也就是调用select_action函数和step函数就够了。更新计算Q表的关键部分是计算target,它就是根据上面的公式计算出Q值的目标值。Q表中的实际值,和目标值肯定不一样,实际值和目标值的差距,我们称之为误差error,需要去尽量减少这种误差。所以要让Q值去基于error来修正。让Q值去贴近target。此处的更新公式也用到了学习率lr,思路类似于神经网络章节中的参数更新。
除了更新Q表之外,函数后面部分也包括了构建新的策略pi,并对新的策略进行评估,这部分代码是和之前没什么区别的。
def sarsa(env,lr = 0.01,episodes=100, gamma=0.9,test_policy_freq=1000):
nS, nA = env.observation_space.n, env.action_space.n
Q = np.zeros((nS, nA), dtype=np.float64)
for i in range(episodes):
state, _ = env.reset()
finished = False
action = select_action(state, Q)
while not finished:
next_state, reward, finished, _, _ = env.step(action)
next_action = select_action(state, Q)
target = reward + gamma * Q[next_state][next_action] * (not finished)
error = target - Q[state][action]
Q[state][action] = Q[state][action] + lr * error
state, action = next_state, next_action
pi = lambda s: {s:a for s, a in enumerate(np.argmax(Q, axis=1))}[s]
if i % test_policy_freq == 0:
print("Test episode {} Reaches goal {:.2f}%. ".format
(i, test_game(env, pi,)*100))
return pi,Q
然后我们来实际的运行代码。
print_policy(policy_sarsa,env)
print('Reaches goal {:.2f}%. '.format(
test_game(env, policy_sarsa)*100))
Policy:
| 00 < | 01 ^ | 02 < | 03 ^ |
| 04 < | | 06 > | |
| 08 ^ | 09 v | 10 < | |
| | 13 > | 14 v | |
Reaches goal 78.00%.
五、Q-Learning算法
Q-Learning算法和SARSA非常像,只不过在计算target时的公式不一样。 $$ 当前Q(S,A) = Reward + 折现系数 * MAX(下一步Q(S,A)) $$ 公式右侧计算下一步Q值时使用了max函数。因为在策略评估阶段时,我们使用的当前策略并不总是选择到最优动作,有时会使用随机动作。所以为了让迭代更快,直接将给定状态下算出的所有行动Q值来取最大,用最大值来代替下一步的Q(S,A)。所以Q-Learning算法会选择到最优的动作进行评估。
在具体实现代码中,我们将select_action进行了优化。引入了temp参数,temp参数的作用在于改变probs的相对大小。从而调节在迷宫中是否要做更多的探索。在同样的Q值分布下,temp参数越大,probs的分布会越平均,各Q值被随机选择的概率差距不会很大,非最优动作也有不小的机会被选中。temp参数越小,probs的分布会越不平均,差距会变大。非最优动作的概率被压缩的很小,基本上只会选择最优动作。
def select_action(state, Q,temp):
Qvalue = Q[state]
scaled_Q = Qvalue / temp
norm_Q = scaled_Q - np.max(scaled_Q)
exp_Q = np.exp(norm_Q)
probs = exp_Q / np.sum(exp_Q)
return np.random.choice(len(Qvalue), p=probs)
再来看核心部分代码q_learning函数。大部分代码和SARSA差不多,只是在计算td_target时,使用了max函数。
def q_learning(env,lr = 0.001,episodes=100, gamma=0.9,test_policy_freq=1000):
nS, nA = env.observation_space.n, env.action_space.n
Q = np.zeros((nS, nA), dtype=np.float64)
temp_array = np.logspace(0,-2,num=episodes)
for i in range(episodes):
state, _ = env.reset()
finished = False
while not finished:
action = select_action(state, Q,temp_array[i])
next_state, reward, finished, _, _ = env.step(action)
td_target = reward + gamma * Q[next_state].max() * (not finished)
td_error = td_target - Q[state][action]
Q[state][action] = Q[state][action] + lr * td_error
state = next_state
pi = lambda s: {s:a for s, a in enumerate(np.argmax(Q, axis=1))}[s]
if i % test_policy_freq == 0:
print("Test episode {} Reaches goal {:.2f}%. ".format
(i, test_game(env, pi)*100))
return pi,Q
最后我们来实际的调用q_learning函数,得到对应的策略函数和Q表。
env = gym.make('FrozenLake-v1')
policy_q_learning,Q_q_learning = q_learning(env,lr=0.01,episodes=50000)
然后把学到的策略函数进行显示和效果测试。
print_policy(policy_q_learning,env)
print('Reaches goal {:.2f}%. '.format(
test_game(env, policy_q_learning)*100))
Policy:
| 00 < | 01 ^ | 02 > | 03 ^ |
| 04 < | | 06 < | |
| 08 ^ | 09 v | 10 < | |
| | 13 > | 14 v | |
Reaches goal 74.00%.
从测试效果可以看到,Q-Learning和SARSA的效果差不多,它们都是利用单步迭代来修正Q表的,其速度和稳定性都比蒙特卡罗要好。Q-Learning和SARSA的区别在于,在策略评估时,SARSA用的就是策略函数所生成的策略,而Q-Learning用的是策略函数所生成的策略的最大值,它会更快的收敛到最优策略上。
我们用一个流程图来总结一下Q-Learning的训练流程。Q-Learning的核心是学习一个优秀的策略函数,表现形式是Q表。主体将当前状态信息输入Q表,得到当前状态行动价值,并选择合适的行动和环境交互。环境产生收益的同时,转换到下一状态。然后将下一状态信息再输入Q表,计算得到下一状态行动价值的最大值。根据公式算出target,target应该和当前状态行动价值一致,如果不一致,就计算差距error,再去修正Q表。
graph TD
当前状态-->Q表-->当前状态行动价值
Q表--选择行动-->环境-->产生收益
环境-->下一状态-->Q表-->下一状态行动价值MAX
当前状态行动价值-->计算error
target-->计算error
下一状态行动价值MAX--> target
产生收益--> target
计算error--更新-->Q表本章小结:
本章主要介绍了强化学习算法来解决冰湖问题。强化学习的应用场景是在主体和环境有交互的场景。主体在环境中行动,环境对这些运行给予延迟的反馈,例如回报和状态信息,主体再基于这些反馈进行下一步行动。主体需要找到一个最优策略和环境交互,最优策略意味着每轮游戏都尽可能拿到最大的回报。强化学习算法要解决的,就是如何去找到这个最优策略。
和第八章类似,基本的思想仍然是试错和修正。因为没有直接针对某个行动的标签反馈,所以我们计算Q值来当作行动的标签。那么Q值的计算就非常关键了。Q值意味着给定某个状态下各行动的长期价值。如何计算Q值有三种方法,第一种是蒙特卡罗方法,它是用一整轮游戏交互的真实结果来计算估计Q值。第二种是SARSA算法,它是用单步交互和迭代递归的方法来估计Q值。第三种是Q-Learning算法,它和SARSA算法非常像,区别只在目标值计算上使用了最优的估计值,它会有更快的收敛速度。
本章介绍的Q值都是以一个矩阵的形式保存,也就是Q表。将状态值输入Q表,可以得到最大值对应的动作。Q表就是一个策略函数。细心的读者应该可以联想到,神经网络也是一种函数,如果把神经网络来代替Q表,让神经网络处理状态输入,计算得到动作输出,是不是更好呢?这就是深度强化学习,它把第八章的神经网络和本章的强化学习Q-Learning进行了完美的结合。我们会在下一章学习深度强化学习的经典算法DQN。