第九章:蒙特卡罗模拟
本章我们将学习人工智能领域的另一部分重要内容,蒙特卡罗模拟。它是一种随机模拟的技术,用于估计不确定事件的可能结果。在计算机出现后,人们更多的使用程序来生成伪随机数,用于更快的完成各种模拟实验。本书前面的内容中已经学习过随机数的使用,例如在贪吃蛇章节中学习用随机值来当做果实的坐标。本章将使用各种代码示例来理解蒙特卡罗模拟的思路。通过程序来模拟投骰子、玩硬币、玩扑克牌的各种随机事件。最后我们会基于蒙特卡罗模拟来构建一个井字棋的AI玩家。
一、什么是随机模拟
生活中我们经常遇到碰运气这个说法,这是因为某些事件具有随机性。所谓随机性是指某个事件的结果可能是这样也可能是那样,我们在事前并不能预测到。例如我们往桌上扔一个硬币,硬币可能正面朝上,也可能反面朝上,在扔这个硬币之前我们是没办法预测到具体的结果的。这种具有随机性的事件我们叫做随机事件。
虽然随机事件的单次结果我们无法预测,但是当这种随机事件发生的次数非常多,有一些基本规律还是可以得到的。还是以扔硬币为例,单次扔硬币的结果无法预测,但是如果说硬币是正常的,扔很多次下来,应该正面和反面的出现次数各占一半左右,这种规律我们是可以得到的。类似扔硬币这种事件,出现正反面结果所占的比率叫做概率,有专门的概率论来研究各种概率,不过我们这次并不会深入学习概率,我们只是以随机模拟的角度来初步尝试一下。随机模拟需要大量的重复随机抽样实验和计算,而计算机正适合于做这种任务。在二战期间,科学家冯·诺伊曼等人为原子弹计划工作时,发明了蒙特卡罗模拟方法。
蒙特卡罗方法一般会有如下四个流程: - 定义可能的输入空间范围 - 在这个范围里,基于某种概率分布,生成大量随机值 - 对每个随机输入值,放入确定性函数中进行计算,得到函数结果值 - 对所有结果值进行汇总统计
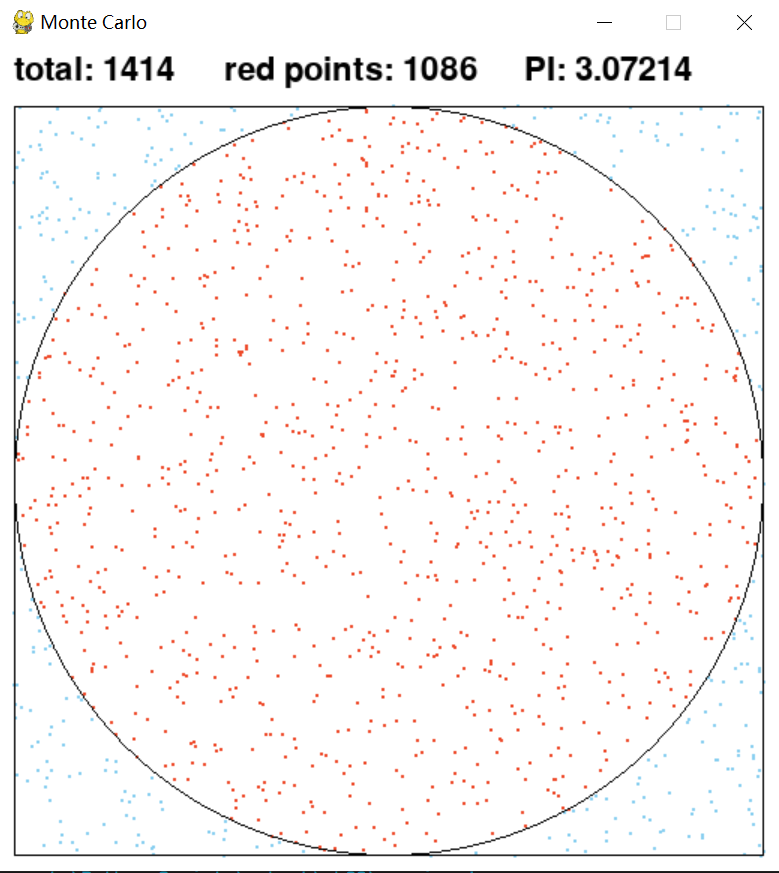
设想这样一个随机模拟实验。我们的目标是用计算机模拟来估计出圆周率。现在我们先在窗口中绘制一个直径单位为1的圆形,再紧贴着圆形外面绘制一个边长等于1的正方形。它们的中心点是一致的。然后我们进入以下四个计算流程。 - 以正方形为输入空间范围 - 均匀的生成随机坐标点,它们都落在这个正方形中 - 计算每一个点和圆心之间的距离 - 统计所有距离在半径之内的点的个数,将这个数字除以所有点的个数
这个统计结果的值是什么意义呢?它其实就约等于圆形的面积。然后我们再用圆面积公式,反推出圆周率的大小。下面我们用PyGame来实现这个编程实验。
代码的核心部分如下,我们在窗口中绘制一个正方形和一个圆形。随后生成两个随机数,构成随机点的坐标。计算随机点和圆心之间的距离,如果距离在圆之内则用红点来绘制随机坐标点,如果在圆之外则用蓝色来绘制随机坐标点。同时对总的随机点和圆内随机点进行计数,再用这两个数字来换算成PI值。将这些信息也显示在窗口上方。
pygame.draw.rect(display_surface, BLACK, (10, 40, 500, 500),width=1)
pygame.draw.circle(display_surface, BLACK, (260, 290), 250,width=1)
x = random.randint(10,510)
y = random.randint(40,540)
radius = math.sqrt((x - 260)**2 + (y - 290)**2)
if radius <= 250:
point_color = RED
in_circle += 1
else :
point_color = BLUE
pygame.draw.circle(display_surface, point_color, (x, y), 1)
total += 1
pi = 4 * in_circle/total
完整的代码可以参考mc_pi.py代码文件。你可以尝试运行这个代码,会发现随着循环的运行次数越来越多,随机点越来越多,PI值会接近真实值。程序实验的窗口截图参考下图。
二、骰子的模拟实验
我们已经学习过了python中的numpy模块。它有一个叫做random子模块,可以用来做各种随机值的模拟和计算。我们先将模块加载进来
random模块中有一个很有趣的函数就是randint,它可以用来随机生成一些整数,使用的时候,需要指定产生随机整数的两边的边界,如果我们要模拟一次掷骰子的结果,假设骰子只有6个面,各自数字是从1到6,那么我们需要在函数中定义好,最小值是1,最大值7,因为最大值并不会出现在生成结果中,所以真实生成的数字就是1到6.
另一种生成1到6的随机数字的方法是使用choice函数,它可以从一个列表或数组中随机选择一下元素。
如果是想模拟生成多个随机数字,可以在函数后面加一个输入参数,表示生成的个数,例如我们想扔骰子连续扔10次,就得到下面的结果,可以看到模拟的结果是一个数组。
也可以用choice来模拟连续扔骰子
计算机是不知疲惫的,我们可以扔10次,干嘛不扔一万次呢,我们可以扔一万次,将结果存到dies变量中
我们想看一下扔一万次骰子的结果到底是怎么样的,可以数一下各自点数出现的次数,也就是说1点出现多少次,2点出现多少次,等等。我们可以写一个函数来计算。func_count函数中,用一个字典来存放最终的结果,先用unique来计算这些生成数组中的去重值,也就是1到6这六个点数,然后用一个循环去遍历观察,每个点数出现的次数,放入字典中。
def func_count(x):
result = dict()
number = np.unique(x)
for n in number:
result[n] = x[x == n].size
return result
{1: 1696, 2: 1679, 3: 1635, 4: 1687, 5: 1649, 6: 1654}
从结果上来看,各种点数出现的次数不完全一样,但是也差不多,说明点数的出现是平均的。
一个骰子的点数是平均出现的,那么2个骰子的点数之和也是平均的吗?我们可以模拟多个骰子,例如下面我们来试试2个骰子。
{2: 262,
3: 578,
4: 799,
5: 1121,
6: 1398,
7: 1618,
8: 1467,
9: 1082,
10: 844,
11: 563,
12: 268}
可以看到这些点数存在一些规律,在点数较小和点数较大的区域,如2点,12点,只有2百多次,7点出现的最多,有1618次,这是为什么呢?因为2点出现的条件是两个骰子都是等于1,这种事件出现的机会比较小,而7点出现的条件就很多了,2+5也可以是7,3+4也可以是7,所以7点出现的机会比较大。
我们可以把上面的函数稍微改一下,计算出各点数出现的次数,相对于总次数的占比,这个占比就是概率,它衡量了某个点数出现的机会。这种两边少中间多分布情况可以称为钟形分布,它和平均分布有很大区别。
def func_prob(x):
result = dict()
number = np.unique(x)
for n in number:
result[n] = x[x == n].size/len(x)
return result
{2: 0.0262,
3: 0.0578,
4: 0.0799,
5: 0.1121,
6: 0.1398,
7: 0.1618,
8: 0.1467,
9: 0.1082,
10: 0.0844,
11: 0.0563,
12: 0.0268}
研究了骰子之和,我们再换个问题,扔两个骰子,扔出两个5都朝上的概率是多少?我们编写如下代码来计算一下。
test_num = 10000
die_1 = rd.randint(1,7,test_num)
die_2 = rd.randint(1,7,test_num)
result = (die_1 == 5) & (die_2 == 5)
sim_prob = result.sum()/test_num
print("模拟概率为{x:.4f}".format(x=sim_prob))
模拟概率为0.0284
让我们换个思路,如果不用计算机程序来计算,而是用数学的思路来思考,某个骰子点数等于5出现的概率应该是1/6,那另一个骰子点数等于5出现的概率为是1/6,所以直接相乘,这就得到了真实的概率。
真实概率为0.0278
从扔骰子的例子看出,当数据量较大的时候,模拟的概率值和真实的概率会非常接近。
三、硬币的模拟实验
玩完了骰子,我们来玩一下硬币,先提出一个问题大家思考一下。如果抛三枚硬币,三枚硬币全为正面或反面的概率是多少?
模拟硬币的代码和骰子是类似的,我们用1来表示硬币的反面,1来表示硬币的正面,可以写出类似的程序,得到三个硬币各扔一万次的结果。
test_num = 10000
coin_1 = rd.randint(0,2,test_num)
coin_2 = rd.randint(0,2,test_num)
coin_3 = rd.randint(0,2,test_num)
这些模拟的结果都是数组的形式,计算数组是否满足某个条件,直接使用==比较操作符,再用&操作符,表示“且”的关系,这样计算出三个硬币都是正面或都是反面的模拟结果,
result_1 = (coin_1 == 1) & (coin_2 == 1) & (coin_3 == 1)
result_2 = (coin_1 == 0) & (coin_2 == 0) & (coin_3 == 0)
(result_1.sum()+result_2.sum())/test_num
0.2527
我们再来看一个稍微复杂一点的问题。假设有人找你玩一个游戏,每人一个硬币,每次两人一起给出正反面
如果: 1. 出现两个正面,你赢 3 块钱 2. 出现两个反面,你赢 1 块钱 3. 出现一正一反,你输 2 块钱
问题是你要不要和他去玩这个游戏?
如果玩这个游戏可以不亏钱,应该就可以玩,先假设两个人给出正反面都是随机给出的,可以模拟一下看看。
test_num = 10000
coin_1 = rd.randint(0,2,test_num)
coin_2 = rd.randint(0,2,test_num)
result_1 = (coin_1 == 1) & (coin_2 == 1)
result_2 = (coin_1 == 0) & (coin_2 == 0)
result_3 = ((coin_1 == 0) & (coin_2 == 1)) | ((coin_1 == 1) & (coin_2 == 0))
可以看到这三种可能的结果,对应的概率大约是1/4,1/4,1/2
2550
2431
5019
然后我们把各结果对应的收益考虑进去,就是各收益直接乘上对应的结果,再求和。
43
看起来没有亏,可以玩起来,但是要注意一点,我们的假设是双方的硬币是随机出正反,有可能对方的硬币并不是随机出现正反的,如果对方一直出现反面会怎么样?
test_num = 10000
coin_1 = rd.randint(0,2,test_num)
coin_2 = np.zeros(test_num)
result_1 = (coin_1 == 1) & (coin_2 == 1)
result_2 = (coin_1 == 0) & (coin_2 == 0)
result_3 = ((coin_1 == 0) & (coin_2 == 1)) | ((coin_1 == 1) & (coin_2 == 0))
amt_result = 3*result_1+1*result_2 +(-2)*result_3
amt_result.sum()
-4991
看起来我们就大亏了,你可以想一想,如果对手使用了一直出反面的策略,我们应该怎么做?
三、扑克牌的模拟实验
基于前述的知识,利用python来写一个抽扑克牌的程序,也就是尝试从一副牌中随机抽取两张牌,计算抽得一对A的概率是多少。然后和真实的概率值进行对比。
下面我们用数组来建立一副扑克,数组中每个元素实际上是一个字典,s表示了花色,n表示了点数。
suit = ['红心','黑桃','方片','草花']
number = ['2','3','4','5','6','7','8','9','10','J','Q','K','A']
cards = np.array([{'s':s,'n':n} for s in suit for n in number])
array([{'s': '红心', 'n': '2'}, {'s': '红心', 'n': '3'},
{'s': '红心', 'n': '4'}, {'s': '红心', 'n': '5'}], dtype=object)
可以使用choice来从数组中模拟随机抽牌。
array([{'s': '黑桃', 'n': '10'}, {'s': '红心', 'n': 'J'}], dtype=object)
下面来写一个函数,计算抽得一对A的概率是多少
def cards_func():
my_card = rd.choice(cards, 2,replace=False)
is_AA = my_card[0]['n'] == 'A' and my_card[1]['n'] == 'A'
return is_AA
模拟概率为0.0047
抽得一对A的理论概率可以这样来思考,52张牌中只有4张A,那么要抽一对A的过程可以分为两步,第一步先从52中抽到4张A的一张,这一步的概率是4/52,第二步是从剩下的51张牌中抽3张A中的一张,这一步概率是3/51。
真实概率为0.0045
从一副扑克牌中抽取5张牌,其中能够凑成 4条的概率是多少?用模拟的方法来程序。
suit = ['红心','黑桃','方片','草花']
number = ['2','3','4','5','6','7','8','9','10','J','Q','K','A']
cards = np.array([{'s':s,'n':n} for s in suit for n in number])
def cards_func():
my_card = rd.choice(cards, 5,replace=False)
is_fore = len(set([c['n'] for c in my_card]))==2
return is_fore
0.0016
可以看到,对于一些略复杂的问题,直接用数学的思路来算有些麻烦。这时我们就可以借助于计算力的暴力,来模拟出结果。
四、蒙特卡罗方法玩井字棋
在第二章我们用python完成了井字棋游戏程序,第八章我们用棋谱完成了一个会下棋的神经网络。本节我们将在没有棋谱的情况下构建一个会下棋的AI机器人。我们先想想人类是如何下棋的。俗语说下棋看三步,人类下棋本质上是评估哪个位置上落子会更有利,而判断是否有利的方式就是在自己大脑里模拟一下,我方走这里,对方可能会如何应对,我方走另一个位置,对方可能会如何应对。
计算机也是一样的。让计算机来下棋,需要设计一种更容易量化的评估方法,能让计算机知道每一个落子位置的价值。以井字棋为例,刚开局的时候棋局状态是空白的,此时计算机应该选择哪个位置落子呢?一种可能的思路就是暴力穷举。在不同位置落子会形成不同的后续局面,如果在A位置开局,而最终能赢下来,说明这个A位置不错。如果在另一个B位置开局,如果最终结果输棋了,说明这个B位置不利。可以给定所有9个可能的开局落子位置,在每个可能情况下遍历所有可能的对手落子位置,以此轮换思考,遍历出所有9个开局状态下的对弈最终结局,然后汇总计算出9个位置所对应的胜负比率。那么一定会有一个胜率最高的开局落子。这样的思路虽然理论上可行,但是遍历次数非常的多,当棋盘较大时是很难快速计算的。
前面学习的蒙特卡罗模拟就可以派上用场了。它作为一种随机抽样的方法,正好能用来代替暴力穷举。在9种可能的开局状态下,双方轮流随机走棋,来得到大量的对弈结局。只要这种随机下棋的对局次数够多,这种随机模拟下的胜率会接近于穷举下的胜率。虽然看起来是胡乱下棋,但初始的局面因素会在一定程度上体现在最终输赢上。这样计算机通过和自己模拟下棋,能评估某个局面是否有利,也就能评估某一步棋是否有利了。归纳下来,计算机在选择落子位置时,会在自己大脑里用随机走棋的方式进行多轮模拟,根据模拟的结果反推当前哪个位置落子的胜率最高,最后会选择这个最优位置进行真实的走棋。
我们在第二章构建了Game类和Board类,在此基础上我们会增加一个AI_tic类。蒙特卡罗模拟玩井字棋的代码设计图示如下。
classDiagram
Game *-- Board : Composition
Game *-- AI_tic :Composition
class Game {
Board
AI_tic
...
}
class Board {
}
class AI_tic {
}
新增的AI_tic类用于构建AI玩家。初始化函数中n_sim是定义了模拟的次数,也就是会运行n_sim次模拟,得到n_sim个胜负结局。size是棋盘大小。getNextMoves函数负责获取当前棋局下有多少个可以落子的选项。基本逻辑就是遍历所有棋盘位置,如果是可以走子的地方,就把这个地方进行标记,作为一个可能的下棋位置,或是一种新的棋盘局面,将这个新的局面保存在nextMoves这个列表中。
class AI_tic:
def __init__(self,n_sim, size):
self.n_sim = n_sim
self.size = size
def getNextMoves(self,currentBoard, player):
nextMoves = []
for i , _ in enumerate(currentBoard.pieces):
if currentBoard.isMoveValid(i):
boardCopy = deepcopy(currentBoard)
boardCopy.setMove(i, player)
nextMoves.append(boardCopy)
return nextMoves
对于上述获取的每个可能的落子选项,计算机都需要评估其价值。评估的方法就是计算机自己左右互搏,模拟下棋得到最终胜负结果。如下的oneSimulation函数就是负责模拟走完一盘棋,其函数参数是给定某个棋局状态和待落子玩家。调用getNextMoves函数,拿到所有可落子的选项后,在while循环中用随机函数randint随机选择其中一个落子位置。调用getNextPlayer来轮换给模拟的对手下棋,对手也会从可选的位置进行随机选择。这样就实现了双方轮换随机下棋的功能。当hasWon函数返回真时,棋局结束,跳出while循环,完成这一盘的模拟下棋对弈。函数返回的结果是两个东西,firstMove是这盘对弈的第一个落子位置,score是这个落子位置的价值。
需要注意的是while循环的条件,条件是nextMoves不为空,也就是说,如果棋盘没有任何空间可以走下一步棋时,将结束循环。另外要注意score得分的计算逻辑,每次走完一步时,score会减1,目标是让较早阶段就能下赢的那步棋,得分相对较高。如果最后获得胜利的玩家不是初始玩家,说明是对手获取,那么说明初始那步棋很糟糕,将分数取负数。
def oneSimulation(self,currentBoard,currentPlayer):
simulationMoves = []
player = currentPlayer
nextMoves = self.getNextMoves(currentBoard, player)
score = self.size * self.size
while nextMoves != []:
roll = random.randint(1, len(nextMoves)) - 1
nextBoard = nextMoves[roll]
simulationMoves.append(nextBoard)
if nextBoard.hasWon(player):
break
score -= 1
player = Game.getNextPlayer(player)
nextMoves = self.getNextMoves(nextBoard, player)
firstMove = simulationMoves[0]
if player != currentPlayer and nextBoard.hasWon(player):
score *= -1
return firstMove, score
getBestNextMove函数是在给定当前局面条件下,找到最佳走棋位置。函数中定义一个字典,在每次循环中,会调用oneSimulation函数,进行一次模拟对弈,拿到该次对弈下的初始落子位置和得分。将初始落子位置做为key,得分作为value,存入字典中。因为棋局对象不方便做字典的key,所以取出pieces属性转成tuple。通过多次模拟对弈,得到每种初始落子位置的累计得分,用于评估决策。最后用max函数来获取累计得分最高的落子位置。
def getBestNextMove(self,currentBoard, currentPlayer):
evaluations = {}
for _ in range(self.n_sim):
boardCopy = deepcopy(currentBoard)
firstMove, score = self.oneSimulation(boardCopy,currentPlayer)
firstMovePos = tuple(firstMove.pieces)
if firstMovePos in evaluations:
evaluations[firstMovePos] += score
else:
evaluations[firstMovePos] = score
bestMove = max(evaluations, key=evaluations.get)
return list(bestMove)
最后修改原来的play函数,当玩家是人类玩家时,我们让玩家去输入落子坐标。当轮到计算机玩家时,调用getBestNextMove函数进行决策。函数返回的棋局数据会给棋局对象board重新赋值。这样修改之后就可以让人类玩家和AI玩家对弈了。你可以试试看能否战胜计算机呢。
def play(self):
self.board.show()
while self.board.hasMovesLeft():
if self.currentPlayer == self.userPlayer:
self.getPlayerMove()
else:
self.board.pieces = self.AI.getBestNextMove(self.board,self.currentPlayer)
self.board.show()
if self.board.hasWon(self.currentPlayer):
print('\n 玩家 ' + self.currentPlayer + ' 胜利!')
break
self.currentPlayer = self.getNextPlayer(self.currentPlayer)
除了人类玩家和AI玩家进行对弈之外,还可以让两个AI玩家之间进行对弈。只需要把play函数做点简单修改即可。
def AIvsAI(self):
self.board.show()
while self.board.hasMovesLeft():
self.board.pieces = self.AI.getBestNextMove(self.board,self.currentPlayer)
self.board.show()
if self.board.hasWon(self.currentPlayer):
print('\n 玩家 ' + self.currentPlayer + ' 胜利!')
break
self.currentPlayer = self.getNextPlayer(self.currentPlayer)
即然AI已经可以互相对弈了,那我们自己就能把这些对弈的棋谱保存下来,供给第八章的神经网络去学习了。编写的函数也不复杂。只是需要将原始的棋局信息用函数replacePieces转换成神经网络需要的格式,然后用落子前后的状态集合去获取落子的坐标位置,保存为变量move。最终用write写入文件。
def AIvsAI_file(self,file):
while self.board.hasMovesLeft():
PiecesBefore = self.replacePieces(self.board.pieces,self.currentPlayer)
boardSet = set([str(i)+x for i, x in enumerate(self.board.pieces)])
self.board.pieces = self.AI.getBestNextMove(self.board,self.currentPlayer)
boardSetPlay = set([str(i)+x for i, x in enumerate(self.board.pieces)])
move = list(boardSetPlay - boardSet)[0][0]
file.write(','.join(PiecesBefore))
file.write(','+move+'\n')
self.currentPlayer = self.getNextPlayer(self.currentPlayer)
在程序主入口处定义一下文件位置,以及定义循环次数即可,此处我们让两个AI互相对弈了五百局。注意这里的对弈是真实的对弈,AI走的每一步棋,都是基于它们多轮模拟的对弈结果,而计算出来的最优落子位置。真实的对弈是深思熟虑的,而模拟的对弈是随机进行的。
if __name__ == '__main__':
with open(r'tic_record.txt', 'w') as file:
for i in range(500):
game = Game(boardSize=3,startPlayer='X')
game.AIvsAI_file(file)
print("-----"+"epoch"+str(i)+"-----")
print("Done")
本章小结:
本章我们学习了蒙特卡罗模拟方法,它是一种随机模拟的技术,用于估计不确定事件的可能结果。我们用Python中的random模块来编写模拟的代码,实现了多个不同场景的模拟效果。例如计算PI值,模拟筛子、扑克牌等等。最后我们用蒙特卡罗模拟方法来构建了一个井字棋的AI玩家。
这种方法和第八章的神经网络下井字棋有很大区别。神经网络下井字棋是有监督学习,训练过程需要棋谱,也就是需要一个老师来帮助它。蒙特卡罗模拟方法不需要棋谱的数据,它可以自学成材,反过来它还能产生AI对弈的棋谱。其核心原理在于计算机通过多轮模拟的随机下棋,计算出各个初始落子位置上的相对价值。然后在真实下棋时,选择价值最高的落子位置。这就是随机模拟的力量。我们会在第十六章使用蒙特卡罗模拟方法来下规模更大的五子棋。本章这种模拟的代码还有可改进之处,我们每次模拟的时候,它们的信息并不是共享的。也就是说,第一轮模拟后得到的落子位置价值信息,并没在第二轮模拟时用上。各轮模拟都是从头开始的。如果能把这些信息累积起来,计算效果将会更上一层楼。我们会在第十六章详细讲解改进后的方法,也就是蒙特卡罗树搜索。这种方法也是阿尔法狗的核心算法模块。
下一章我们会进入一个新的人工智能领域,也就是强化学习。强化学习有能完全靠自己自学成才,他需要另一种独特的标签帮助。我们会用强化学习来构建多个游戏中的AI玩家。