第八章:神经网络和PyTorch基础
从本章开始,我们将学习人工智能的基础知识,人工智能领域体系庞杂,我们选择了几个核心的内容进行学习。分别是深度强化学习、遗传算法和蒙特卡洛算法。深度强化学习是深度学习和强化学习的结合。深度学习是利用结构复杂、层级很深的神经网络为核心主体,结合相关训练技术的算法领域。在本书中并不严格区分深度学习和神经网络。本章将介绍神经网络。我们会学习神经网络的基本原理和应用场景,同时我们会学习PyTorch模块,并学习用PyTorch来搭建神经网络。不过在此之前,我们会先从最优化方法来切入。
一、最优化方法
什么是最优化
通俗来讲,最优化就是把某件事做到极致做到最好。具体而言,做任何事情都有一个目标,也会有很多因素来影响这个目标。例如在办公楼内工作的时候,物业管理人员的一个目标就是让人的体感舒适度最佳,影响这个目标就包括了室内的温度和湿度等因素。需要找到一组最适合的温度和湿度,使体感舒适最好。这时候,可以将体感舒适度看做是温度和湿度的函数。从数学角度来讲,最优化就是控制函数的变量,以找出函数值的极值。
我们先看一个普通的二次方函数,例如 \(y=x^2\),我们想知道它的最小值在哪里。从下面的图可以看到,当x取0的时候,这个函数取值最小。我们可以用matplotlib模块来把这个函数画出来看看。
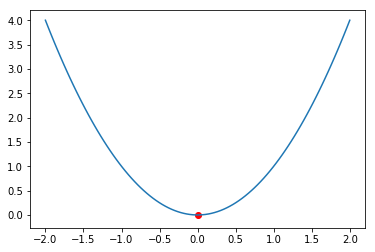
更形象的解释就是,如果把这个函数看作是一个山谷,有一个生活在这的山羊,山羊希望能跑到山的最低洼地方去。如果它的视力非常好,可以一眼看到山的最低处就可以直接去那里。但是如果它的视力又不好,一眼看不到最低处,只能看到眼前的地方,那有什么办法可以到达最低处呢?这个问题中,可以控制的因素是行走的方向和大小。目标是要走到最低处。
梯度下降算法
如果山羊的视力看不见山谷,但是可以看到近处,那么它会知道在它现在所处的这个地方,地势的高低走向是怎么样的。因为它生活在这个二维的山上,它只有两个方向可以选择,向左走或是向右走。它可以观察到近处左边的地势和右边的地势。可以这样来思考一下,如果左边的地势比右边的地势低,那么有可能低洼处就在左边某个地方,所以从贪心算法的思想来看,我们就以当前位置的局部地势来判断,往左边较低处的方向走。往左走了一步之后,再从当前位置观察局部地势,再进行判断决策。就这样循环往复,最终可能会找到山的最低处。
如果要编程来模仿山羊的行动决策,我们还需要明确两个具体的东西,一是如何来判断局部的地势以决定走的方向,二是如何决定走的步子大小。
对于第一个问题,我们可以联想到斜率这个概念,如果在山谷的某个位置上,或者说在函数的某个点的位置上,这个点对应的斜率是可以算出来的,如果斜率是正数,说明左边比右边低,方向选择上就应该往左走,反之,如果斜率是负数,说明左边比右边高,方向选择上应该往右走。斜率在数学上也称之为导数或者梯度。所以总结成一句话,梯度下降算法的核心思想,就是沿着当前位置的梯度方向的反方向走,因为这个方向是高度较低的方向。
对于第二个问题,可以想像的到,如果步子小,我们需要更多的步数才走到底部,如果步子大,可能需要较少的步数,但是呢,步子越大,可能会越过底部,走过头了。所以通常我们会设置一个较小的步长。步子决定了我们从当前位置更新到新的位置的速率,也称之为学习率。
如果用一个公式来描述上述的思路就是: $$ 新的位置 = 当前位置 - 步长\times 斜率 $$ 用代码来表达位置的更新方式如下:
等号右侧的x是当前位置,rate是步长,gx是当前位置的斜率,在每一步,我们会算出当前位置的斜率gx,当gx为正也就是斜率为正,我们应该往左走,自然就是在当前位置上做减法,x就会变小;如果gx为负也就是斜率为负,和前面那个负号抵消后成为一个加法,x就会增加,就是往右走。从这个公式出发,图中的山羊就应该往左走一小步。
下我们用代码来实现一下这个过程。这个函数代码是上述的梯度下降思路来求某个函数的最小值。输入参数有四个,x_start表示初始点的位置,也就是山羊一开始的位置,rate是步长或学习率,n_iter是走的步数或迭代次数,f是需要求最小值的那个函数,也就是山谷的形状,g是f的梯度函数,也就是对应山的每个位置的斜率可以通过g算出来。
def min_gradient(x_start, rate, n_iter, f,g):
x = x_start
for n in range(n_iter):
gx = g(x)
y = f(x)
x = x - rate*gx # 梯度下降
print("X:{x:.2f}, Y:{y:.2f},gx:{gx:.2f}".format(x=x, y=y,gx=gx))
if abs(gx)<0.0001:
break
return x
在进入循环之后,每一步,我们会算出当前位置的斜率,存在gx中,再算出当前的高度y,再用一个梯度下降公式去修正x的值,因为gx为正也就是斜率为正,我们应该往左走,自然就是在当前位置上做减法,如果gx为负也就是斜率为负,和前面那个负号抵消后成为一个加法,x就会增加,就是往右走。
同时为了显示每一步的信息,我们打印出这几个变量的值,以方便我们调试和理解,最后有一个条件判断,当斜率非常小的时候,说明地势已经很平了,可能已经到最低点了,可以提前终止。
为了计算平方函数的最小值,我们需要定义这个二次方函数,存放在f中,同时定义好二次方函数对应的梯度函数。梯度函数g就是对f的求导结果。然后我们假设小兔子在二次方曲线这个山上,它的起始点是x等于2这个地方,学习率设置为0.1,让它走10步,看一下函数计算的中间过程和最终结果。
X:1.60, Y:4.00,gx:4.00
X:1.28, Y:2.56,gx:3.20
X:1.02, Y:1.64,gx:2.56
X:0.82, Y:1.05,gx:2.05
X:0.66, Y:0.67,gx:1.64
X:0.52, Y:0.43,gx:1.31
X:0.42, Y:0.27,gx:1.05
X:0.34, Y:0.18,gx:0.84
X:0.27, Y:0.11,gx:0.67
X:0.21, Y:0.07,gx:0.54
0.21474836480000006
如果初始点为2,学习率为0.1,走10步,我们会发现由于每一步走的比较小,最后我们走到了x=0.21这个位置,此时比较靠近0了,但是并未达到最小值0。不过从打印的信息中可以看到,x是慢慢靠近0的,而且y也是在减小的,说明走的方向是对的,只不过还没走到。这时我们可以调大迭代次数,或是调大学习率。
X:0.80, Y:4.00,gx:4.00
X:0.32, Y:0.64,gx:1.60
X:0.13, Y:0.10,gx:0.64
X:0.05, Y:0.02,gx:0.26
X:0.02, Y:0.00,gx:0.10
X:0.01, Y:0.00,gx:0.04
X:0.00, Y:0.00,gx:0.02
X:0.00, Y:0.00,gx:0.01
X:0.00, Y:0.00,gx:0.00
X:0.00, Y:0.00,gx:0.00
0.00020971520000000014
将学习率调整到0.3之后,发现x已经非常接近0了,目标达到了。如果学习率设置再大一些会不会更快一些呢?当我们将学习率调整到1.1之后,发现不仅没有接近最小值,反而越走越远。这是因为学习率设置的过大,出现震荡现象。
X:-2.40, Y:4.00,gx:4.00
X:2.88, Y:5.76,gx:-4.80
X:-3.46, Y:8.29,gx:5.76
X:4.15, Y:11.94,gx:-6.91
X:-4.98, Y:17.20,gx:8.29
X:5.97, Y:24.77,gx:-9.95
X:-7.17, Y:35.66,gx:11.94
X:8.60, Y:51.36,gx:-14.33
X:-10.32, Y:73.95,gx:17.20
X:12.38, Y:106.49,gx:-20.64
12.383472844800014
最后总结一下,梯度下降是一种寻找函数极值的思路,它通过沿着负梯度方向移动来找到最低点。梯度下降算法需要知道三个因素后进行循环计算,以逼近极值。这三个因素分别是初始的位置,函数的导数,学习率。如果学习率设置的过小,会花费很多步数才会到达极值,如果学习率设置过大,会导致无法到达极值位置。我们一般会设置一个较小的学习率,用较大的迭代次数来计算。
二、PyTorch基础知识
什么是PyTorch
PyTorch是人工智能领域最常用的算法框架,它类似于Numpy这种用于科学计算模块,这类模块中包括了各种方便的函数,让我们像是搭积木一样很快的搭建所需要的AI算法模型。PyTorch的出现降低了入门的门槛,同学们不需要从基础底层的神经网络开始编代码,可以依据需要,使用已有的函数或模型。
PyTorch的优点主要有两个:
- 简洁优雅:PyTorch的设计追求最少的封装,尽量避免重复造轮子。PyTorch的代码更短,更易于编写和理解。
- 活跃的社区:PyTorch提供了完整的文档,循序渐进的指南,互联网上有大量资料,供用户交流和求教问题。。
PyTorch模块的安装可以直接通过官网下载安装。官网地址为https://pytorch.org/
进入网站后,在如图所示的地方选择对应的版本和操作系统。

以上图为例,如果我们选择Windows系统,和CPU计算平台,它会提示你的命令行信息:“pip3 install torch torchvision torchaudio” 。在命令行窗口下,把这句代码输入进去后,即会进行联网安装。完成后进入python环境,输入加载PyTorch的命令,没有报错即说明安装成功了。
PyTorch的张量操作
PyTorch的基本操作对象是张量,也称为tensor。tensor类似于numpy模块中的array,不过在torch中的tensor还可以利用GPU的计算能力。我们来看一些操作张量的例子。
此处代码,生成了一个5行3列的元素全为1的矩阵,这个生成方式非常像numpy的语法。
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]], dtype=torch.float64)
也可以从numpy中的数据来转换成tensor,下面的代码中用numpy生成一个随机矩阵,再转换成tensor。转换的时候可以使用torch.from_numpy,可样更加节省内存。也可以使用torch.tensor进行转换,不过它会复制一份数据出来。
import numpy as np
np.random.seed(1)
y_array= np.random.randn(5,3)
y_tensor = torch.from_numpy(y_array)
print(y_tensor)
tensor([[ 1.6243, -0.6118, -0.5282],
[-1.0730, 0.8654, -2.3015],
[ 1.7448, -0.7612, 0.3190],
[-0.2494, 1.4621, -2.0601],
[-0.3224, -0.3841, 1.1338]], dtype=torch.float64)
torch包含了常用的运算函数,例如加法,可以直接通过torch下的add函数进行操作,也可以使用add_方法进行操作,add_方法会将加法后的结果保存到x_tensor对象中。
tensor([[ 2.6243, 0.3882, 0.4718],
[-0.0730, 1.8654, -1.3015],
[ 2.7448, 0.2388, 1.3190],
[ 0.7506, 2.4621, -1.0601],
[ 0.6776, 0.6159, 2.1338]], dtype=torch.float64)
tensor([[ 2.6243, 0.3882, 0.4718],
[-0.0730, 1.8654, -1.3015],
[ 2.7448, 0.2388, 1.3190],
[ 0.7506, 2.4621, -1.0601],
[ 0.6776, 0.6159, 2.1338]], dtype=torch.float64)
和numpy类似,porch本身也可以生成随机数。torch中也有和numpy类似的矩阵计算函数,比如matmul,就是可以将两个矩阵进行乘法的操作。
torch.manual_seed(1)
x_tensor = torch.randn(1, 4)
print(x_tensor)
y_tensor = torch.randn(4, 1)
print(y_tensor)
tensor([[ 0.2857, 0.6898, -0.6331, 0.8795]])
tensor([[-0.6842],
[ 0.4533],
[ 0.2912],
[-0.8317]])
tensor([[-0.7986]])
tensor也可以像array一样进行选择切片操作。
tensor也可以自由的转换行列数
一个torch的tensor格式数据,可以通过tolist转换为普通的python的列表格式,也可以通过numpy方法转换为array格式
PyTorch提供的函数极为丰富,有兴趣的同学可以去官网查看文档学习。
自动梯度计算
PyTorch的一个重要特点是可以自动计算梯度。我们在本章第一小节介绍过梯度,所谓梯度可以理解为一个值相对于另一个值的斜率或者说变化率,比如说一辆车在一段时间T内,以某个速度V进行运动,移动了L米距离。那么L相对于T的梯度就是V,这种意义上的量在数学上叫做梯度或是叫做导数。在第一小节中我们是通过人工来定义出梯度的,但PyTorch可以帮助我们自动计算梯度,在解决最优化一类问题时十分方便好用。
下面我们来看一个简单示例,假设x等于3,y是x的一个函数,y是x的平方。定义好二者关系后,我们用backward来自动计算梯度。如果你熟悉微积分的话,你会知道这个梯度应该是等于2*x,也就是等于2*3等于6,然后我们打印出来梯度,的确是等于6。
x = torch.tensor(3.0, requires_grad=True) # 定义一个值为3的tensor名字叫作x
y = x*x # 定义y和x的关系
y.backward() # 自动计算梯度
print(x.grad) #打印y相对于x的梯度
tensor(6.)
要注意一点是,保存在tensor中的梯度会累积起来,如下例,我们有另一个函数z,再计算一次backward后,x的梯度累积了两个梯度的计算。
tensor(12.)
所以正确的做法是加一个梯度信息清零操作。
tensor(6.)
用Pytorch进行最优化
在第一小节的时候,我们写了一个最优化函数来计算最小值,这个最优化函数就是使用了梯度下降的原理,那么即然PyTorch可以自动计算梯度,用它来完成最优化就最好不过了。现在我们来利用pytorch来计算这个二次方函数的最小值。
这个函数定义和之前类似,不过PyTorch要求计算的所有数据都是张量tensor类型,所以在一开始要将初始值x_start转换成tensor格式。进入迭代循环后,计算出最优化的目标值y,然后计算出梯度值gx,再根据梯度值修正得到新的x。
def min_gred(x_start, rate, num, f):
x = torch.tensor(x_start, requires_grad=True)
for n in range(num):
y = f(x)
y.backward() # 计算梯度
gx = x.grad.tolist() # 取出梯度
newx = x.tolist() - rate*gx # 修正
x = torch.tensor(newx, requires_grad=True) #重新定义x, 所以不需要清零操作
print("X:{x:.2f}, Y:{y:.2f},gx:{gx:.2f}".format(x=x, y=y,gx=gx))
if abs(gx)<0.0001:
break
return x
X:1.60, Y:4.00,gx:4.00
X:1.28, Y:2.56,gx:3.20
X:1.02, Y:1.64,gx:2.56
X:0.82, Y:1.05,gx:2.05
X:0.66, Y:0.67,gx:1.64
X:0.52, Y:0.43,gx:1.31
X:0.42, Y:0.27,gx:1.05
X:0.34, Y:0.18,gx:0.84
X:0.27, Y:0.11,gx:0.67
X:0.21, Y:0.07,gx:0.54
tensor(0.2147, requires_grad=True)
可以看到,我们用PyTorch成功的接近了函数的最小值。本例主要出于学习的目的,手动获取了梯度值,再手动更新修正的。在一般情况下,我们不需要这样麻烦。后续的例子会看到正常的代码写法。
三、神经网络
神经网络是什么
神经网络这个概念来源于人类自身的神经系统,人体有各种感知器官来收集外界的信息,然后通过神经系统传送信息,汇总到大脑处进行计算,由大脑结合考虑各类信息后进行决策。这种汇总信息进行计算处理的方法,如果用计算机来模拟的话,就称之为人工神经网络。
想像我们人类是如何学习把球投入篮框的,我们会利用各种感知器官来收集关于投篮的信息,比如球的重量,篮筐的距离等等。根据这些外界信息来决定我们投篮的方向和力量。我们第一次投篮不一定会成功,我们会进一步看看我们实际投篮命中的地方和篮筐距离有多远,我们会根据这种差距来修正下一次出手的方向和力量。这就是利用试错和修正来学习完成任务的。人工神经网络也是一样的道理。
人工神经网络也是需要根据一些外界输入信息,来输出决策。其核心步骤包括两个部分,其一是从输入到输出的计算过程,这个过程称之为前向计算。这个计算过程可能很简单也可能很复杂。最简单的计算可能就是把输入数据进行加权求和。另一部分是根据输出结果和真实值之间的差距,来修正计算函数,这个过程称之为后向修正。前向计算和后向计算轮流迭代,这个过程称为训练过程。就像是我们练习投篮一样,一开始神经网络效果肯定不好,训练一段时间后效果会不断提升。
训练过程中涉及到几个概念需要在下面澄清一下。
-
输入(input):输入给神经网络的外部信息,通常我们用X表示。投篮例子中是外界信息,例如球的重量,篮筐的距离。
-
目标(target):准确真实的结果,通常用Y表示,投篮例子中,目标就是指篮筐进框的位置。
-
预测(predict):神经网络前向计算后得到的结果,投篮例子中,预测就是人类投球命中的位置。
-
模型(model):神经网络从输入到预测的计算逻辑或计算函数。函数是有参数的,例如加权求和计算中的权重。投篮例子中,参数类似于人类投篮的方向和力量。不同的投篮距离需要调整不同的参数,以准确命中目标。
-
损失(loss):模型的预测值和真实目标值之间的差距就是损失。损失越大说明模型不好需要修正。投篮例子中,损失就类似于人类投球命中的位置和篮筐的距离。
-
优化(optimize):一个良好的模型需要有较小的损失,所以如何进行反向修正就是一个最优化的问题,优化的目标是损失的大小,可以调整的是模型的参数。投篮例子中,人类就是不断调整投篮方向和力量参数,来优化投篮命 中率。
由于这类训练过程都需要一个真实值来计算损失,这真实值又被称为目标(target)或标签(label)。这种目标或标签在模型训练中的角色就像是学校中的老师一样,他会监督算法的学习训练过程。所以这类有标签的训练过程称这有监督学习。
矩形周长问题
我们先来看一个估计问题。我们都知道矩形周长,受到矩形的长和宽这两个因素的影响。也就是说它们三者之间存在着这样一个关系。 $$ 矩形周长 = w_1\times 矩形长度 + w_2\times 矩形宽度 $$ 学习过小学数学的同学都应该知道,w1应该等于2,w2也应该等于2。想像这样一种场景。有一台计算机并没有学习过数学,但我们可以给他很多个矩形的长宽和周长,它能否自己归纳估计出w1和w2的值呢。这就是典型的根据数据,归纳规律的问题。让我们来试一下。
首先我们来随机生成20个矩形的长度和宽度,这里使用了随机数来生成一个20行2列的数组。然后计算出这20个矩形的周长,保存在y中。当然这些数据是怎么生成是只有我们人类知道的,计算机只会看到输入的X和y。
w1和w2这些称之为模型的参数W。神经网络一开始并不知道真正的W,那么它会预设一个初始的W。然后进行前向计算,即根据输入的长度宽度,来计算出预测的周长。这个预测值设为f(x),它并不是真正的周长。一开始,预测的周长和真实的周长肯定不一样。它们之间存在差距,也就是损失。这个损失越大,说明估计的W越差。损失越小,估计的W越好。如下式子就是神经网络中设置的模型,也就是从输入到输出的函数形式,这个函数的参数W是未知的,但函数形式一般是可以预设成这种加权求和的形式。 $$ f(x) = w_1\times x_1 + w_2\times x_2 $$
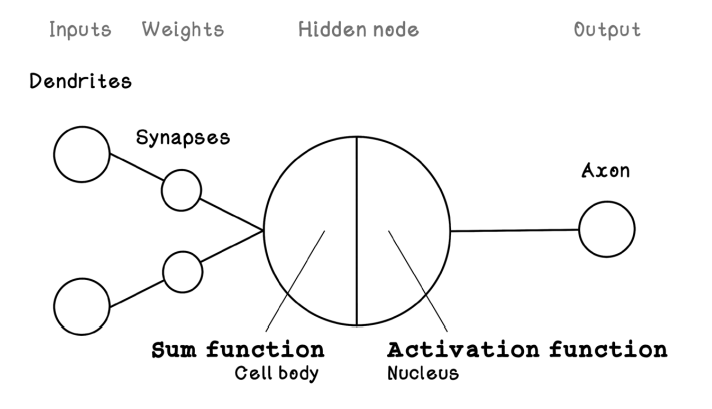
可以用下图来表示这个函数的意义,类似于生物学意义上的神经元,在输入层有两个负责接受输入信息的神经元,也就是x1和x2,有一个负责汇总的神经元,也就是函数f(x),这几个神经元之间的连接强度就是权重参数w1和w2。汇总后的神经元可以再经过一些函数过滤或直接输出。那些负责过滤的函数称之为激活函数。我们会在更后的代码例子中看到。
神经网络会拿到20个矩形,也会算出20个差距,有的差距是正值,有的差距是负值。我们用一个公式来综合汇总一下,这个计算公式是真实值和预测值之间做减法再平方后求均值,称之为MSE。它的含义就是真实值和预测值之间距离越大,这个MSE越大,也就是说预测效果越差,所以我们希望调整模型参数w,使MSE最小。 $$ MSE = \sum_{i=1}^{n} (y-f(x))^2 $$ 如果用具体的代码来表示就是下面计算
这个W的估计问题就可以转换为最优化问题了。把MSE看作是优化的对象,也就是那座山谷的高度就是MSE。那些权重参数W就是山谷中的位置。我们通过梯度下降的方法来找到一组最好的W,让MSE最小。具体的训练流程步骤如下:
- 先给W赋一个随机的初始值
-
计算给定W下的模型预测值,进行一轮前向计算。
-
计算模型预测值和真实目标值之间的差距,我们叫做损失函数,本例中就是MSE。
-
根据损失函数来对W求导,根据梯度下降算法来修正W。完成一轮后向修正过程。
每次迭代权重参数以梯度下降方式更新,具体更新公式为:$$ w = w + rate * (y-f(x))*x$$
具体实现代码如下,构建一个神经网络类,初始化函数中包括了学习率、迭代次数、权重参数和损失值。注重初始的权重W是随机赋值的。
class NeuralNet_Simple:
def __init__(self, dim,rate=0.1, n_iter=20):
self.rate = rate # 步长,学习速率
self.n_iter = n_iter # 迭代次数
self.W = np.random.randn(1, dim) # 代表被训练的系数
self.MSE = [] # 用于保存损失的空list
类中包括两个重要的函数方法,predict是负责前向计算的函数,它只需要做加权求合就可以了。这里是使用了矩阵方法来做更为快速。fit是负责训练函数,它会用初始的W来计算预测值,再根据预测值和真实值之间的损失来计算梯度,根据梯度下降方法来后向修正W,同时记录损失值的大小。
def predict(self, X): # 给定系数和X计算预测的Y
output = np.dot(X, self.W.T)
return output
def fit(self, X, y): # 训练函数
for i in range(self.n_iter):
output = self.predict(X) # 计算预测的Y
errors = y - output
g = np.dot(errors.T, X)
self.W += self.rate * g # 根据更新规则更新系数
self.MSE.append((errors**2).sum()) # 记录损失函数的值
simple_nn = NeuralNet_Simple(dim = X.shape[1], rate=0.001, n_iter=30)
simple_nn.fit(X, y); # 喂入数据进行训练
print(simple_nn.W)
可以将对象中的MSE属性打印出来观察,可以发现和最优化中表现的类似,一开始估计的周长和真实的周长之间差距比较大,但随着训练迭代次数不断增长,这种差距越来越小。
最后我们可以使用predict函数来预测,当一个矩形的长宽分别是3和4的时候,其预测周长是多少。可以看到预测值和真实值相差不多。说明这个模型是不错的。通过数据和神经网络算法,学习到了矩形长宽这两个因素和周长之间的内在逻辑关系。
我们总结一下这个问题中的相关概念。
-
输入(input):输入给神经网络的外部信息,本例中是20个矩形的长度和宽度。
-
目标(target):准确真实的结果,本例中是20个矩形的周长。
-
预测(predict):神经网络前向计算得到的结果,本例中就是神经网络的预测矩形周长预测值。
-
模型(model):神经网络从输入到预测的计算逻辑。这个计算逻辑有两部分构成,一部分是函数形式或网络结构,它是先验给定的,另一部分是函数参数,它是是训练得到的。本例中的模型函数形式就是加权求和,其参数就是W。
-
损失(loss):模型的预测值和真实目标值之间的差距就是损失。本例中就是计算的MSE。
-
优化(optimize):本例中优化的目标是MSE,优化的方法就是梯度下降方法。
这些概念在训练流程中的关系可以用下图表示。输入input和目标target都是外界提供的数据信息data,将信息喂入神经网络模型model,模型是由两个部分确定的,一个是网络结构,也就是函数形式,本例的网络结构就是加权求和函数,另一个是参数,模型参数就是权重W。初始的权重是随机赋值的,用初始的权重结合外界信息,进行前向计算,得到不那么准确的预测值。再根据预测值和目标值来计算损失loss,再用梯度下降方法去修正w,从而找到loss的极小值。最终多轮训练后让模型效果变好。
graph LR
subgraph 数据
输入
目标
end
subgraph 模型
网络结构
网络参数
end
输入-->模型-->预测
目标-->损失计算
预测-->损失计算
损失计算--参数优化-->模型
神经网络的训练过程和学生学习的过程很类似,学生做题目,老师进行批改,计算成绩,然后学生再去订正,修正自己的知识。
graph LR
subgraph 数据输入
练习题输入
正确答案输入
end
练习题输入-->学生-->答题输出
正确答案输入-->计算成绩
答题输出-->计算成绩
计算成绩--修正知识-->学生如果我们换一个估计问题,让计算机学习矩形长宽这两个因素和面积之间的内在关系,它也能学会吗?你可以尝试一下。
这里代码重新设置了X和y_area,注意到y_area的值是由长度和宽度相乘积得到的。你可以再用上面的算法重新来计算一下,看MSE能不能减小,看predict能不能算出接近真实的面积值。
pytorch解决周长问题
前面的例子中,我们编写了一个类,来编写了前向计算和后向修正的代码。其中的梯度计算也是自己定义的。自己定义梯度比较麻烦。第二小节中我们知道Pytorch可以自动计算梯度,下面我们修改一下这个神经网络。这就好比以前我们爬山是自己双腿爬上去的,很辛苦但是很锻炼,这次呢我们是坐缆车上山就方便很多了。
首先加载torch等几个需要的模块,其中torch.nn是重要的一个子模块,我们会调用其中的函数来构造神经网络模型。然后定义几个超参数,要解决的问题是两个输入变量x和一个输出变量y,所以input_size是2,output_size是1,另外我们先定义好整体的迭代次数是30次,学习率是0.001。所谓超参数就是人为先验设定的参数,它们会影响模型表现,但它们不是通过数据训练得到的。神经网络结构也可以认为是一个超参数。
import torch
import torch.nn as nn
# 定义超参数
input_size = 2
output_size = 1
n_iter = 30
learning_rate = 0.001
之后是定义神经网络的结构,直接使用了pytorch内置的Linear类来生成一个model对象。Linear类就是线性加权模型,基本等价于汇总求和。然后定义如何来计算损失函数,损失函数直接使用了自带的MSELoss函数。最后定义了最优化器,参数中包括要修正的参数是模型的参数,以及学习率。定义好优化器后,只需要调用它即可,不用自己写优化部分代码了。
# 定义模型
model = nn.Linear(input_size, output_size, bias=False)
# 定义损失函数和最优化方法
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
训练部分也很简单,将大部分代码放在一个循环中,将输入数据转换为pytorch需要的格式,然后使用model计算出预测值,将预测值和真实值计算损失。再根据这个损失来调整参数。这里根据损失修正参数的代码非常简洁,只需要清空梯度,调用loss的反向函数backward,这一步实际上就意味着计算梯度,再调用优化器的step函数,这一步意味着根据梯度去修正各个参数。从最终打印的结果可以看到,损失函数是逐步减少的,说明训练是有效的。
# 训练
for epoch in range(n_iter):
# 数据转换
inputs = torch.from_numpy(X).to(torch.float)
targets = torch.from_numpy(y).to(torch.float)
# 前向过程
outputs = model(inputs)
loss = criterion(outputs, targets)
# 后向过程
optimizer.zero_grad()
loss.backward()
optimizer.step()
print ('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, n_iter, loss.item()))
pytorch解决面积问题
下面我们来看一下,如何基于pytorch来构建一个神经网络,然后用这个神经网络来解决面积问题。首先加载一些必要的模块。
import torch
import torch.nn as nn
X = np.random.randint(1,10,[20,2])
y_area = X[:,0]*X[:,1]
y_area= y_area.reshape(20,1)
成生对应的矩形长度宽度数据,以及对应的面积数据
和之前内容一样,我们定义几个重要的超参数。
class NeuralNet(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.activate = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
out = self.fc1(x)
out = self.activate(out)
out = self.fc2(out)
return out
来构造一个类名字叫作NeuralNet,类的逻辑就定义了一个模型是如何汇总计算的,这个类的角色就和我们前面定义的model函数是一样的。
model = NeuralNet(input_size, hidden_size, output_size)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
然后使用这个类构造了一个model实例。所以这个实例的构造就不需要自己再去写矩阵相乘,也不需要写参数定义这些代码。和之前一样定义了损失函数和优化器
# 训练
for epoch in range(n_iter):
# 数据转换
inputs = torch.from_numpy(X).to(torch.float)
targets = torch.from_numpy(y_area).to(torch.float)
# 前向过程
outputs = model(inputs)
loss = criterion(outputs, targets)
# 后向过程
optimizer.zero_grad()
loss.backward()
optimizer.step()
print ('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, n_iter, loss.item()))
和之前一样我们用一个循环来进行计算训练。
四、神经网络玩井字棋
从前面小节内容我们了解到,神经网络的作用就在于,给它一些数据。它能从中学习到输入和输出的逻辑关系。这种逻辑关系不一定完全正确,也是一种相当不错的近似。那么神经网络可以玩游戏吗?当然是可以的。我们在第二章已经遇到过井字棋游戏了,但是神经网络用于有监督学习中,需要标签数据。如果我们能得到一些棋谱数据,我们就知道在给定某个棋局下,较好的应对落子是哪个位置。下面我们来尝试基于井字棋的对弈数据来构建神经网络。
井字棋的对弈数据为tic_record.txt文件,可以从本书配套的代码下载地址得到。我们先通过pandas模块来读取这个文件。
import pandas as pd
columns_name = ['x'+str(i) for i in range(9)]+['y']
tic_data = pd.read_csv('tic_record.txt',names = columns_name)
然后可以查看前几行信息
x0 x1 x2 x3 x4 x5 x6 x7 x8 y
0 0 0 0 0 0 0 0 0 0 5
1 0 0 0 0 0 -1 0 0 0 4
2 0 0 0 0 -1 1 0 0 0 2
3 0 0 -1 0 1 -1 0 0 0 8
4 0 0 1 0 -1 1 0 0 -1 0
这个数据共有十列,从x0到x8的九列数据,是表示了当前棋局的状态,每列数据表示的是棋局9个空格的位置。其中如果没有棋子占据,用0表示,如果有我方棋子占据,用1表示,如果有对方棋子占据,用-1表示。而最后一列数据y,则表示在当前棋局状态下的落子位置。所以这个数据的输入是9个变量,所以输入维度是9,而输出是需要从9个位置中选择一个,输出维度也是9.
下面先把输入数据和输出目标数据拆开。
然后定义算法的超参数,定义了输入维度和输出维度,定义了隐层维度,迭代次数,以及学习率。
之后我们来定义神经网络的类。
class NeuralNet(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.activate = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
out = self.fc1(x)
out = self.activate(out)
out = self.fc2(out)
return out
def save(self, file_name='model.pth'):
model_folder_path = './model'
if not os.path.exists(model_folder_path):
os.makedirs(model_folder_path)
file_name = os.path.join(model_folder_path, file_name)
torch.save(self.state_dict(), file_name)
对模型进行实例化,定义优化器
model = NeuralNet(input_size, hidden_size, output_size)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
随后我们对神经网络喂入数据,进行训练。
# 训练
for epoch in range(n_iter):
inputs = torch.from_numpy(X).to(torch.float)
targets = torch.from_numpy(y).to(torch.long)
# 前向过程
outputs = model(inputs)
loss = criterion(outputs, targets)
# 后向过程
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 验证效果
if (epoch>0 and epoch%50==0):
print ('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, n_iter, loss.item()))
with torch.no_grad():
_, predicted = torch.max(outputs, 1)
correct = (predicted == targets).sum().item()
total = targets.size(0)
print('Accuracy of the network : {} %'.format(100 * correct / total))
从模型效果可以看到,准确率为75%左右,虽然不是很高,已经可以用一下了。
最后我们用一条数据来试试看,输入数据是全部为0的棋局,也就是没有任何棋子落下,将数据转换格式,再输入模型进行预测,取出最有可能的落子位置,这个位置是不错的选择。
currentBoard = np.array([[0,0,0,0,0,0,0,0,0]])
input = torch.from_numpy(currentBoard).to(torch.float)
output = model(input)
_, predicted = torch.max(output, 1)
print(predicted)
本章小结
本章我们学习了最优化方法,它是通过调整变量去寻找函数极值的方法。梯度下降算法是一种常用的最优化算法,其基本思路是根据函数的负梯度方向去逐步调整变量,因为负梯度方向是会让局部函数值下降的方向。所以计算函数的梯度成为最优化的关键步骤,我们可以通过数学知识来自行计算,也可以通过PyTorch模块来帮我们自动计算梯度,这个功能对于大规模的梯度计算非常重要。
神经网络是一种模仿人类神经系统的信息处理方法。它的核心思想是通过汇总外部信息,前向计算得到预测值,再根据预测值和真实标签之间的差距,进行后向修正计算,来调整网络参数。具体调整参数的步骤就是利用之前学习的最优化算法,以及PyTorch模块。将损失看作我们要优化的对象,将网络参数看作是影响损失的因素。它的计算本质上体现了不断试错修正的思想。这个训练过程称为有监督学习。
最后我们用学到的神经网络算法运用到井字棋上。给神经网络输入井字棋的对弈棋谱数据,让神经网络能根据棋局状态输出正确的落子位置。大家可以尝试将训练好的网络,和第二章的井字棋代码进行整合,看你能否编写一个和AI对弈的游戏呢。另外,你也会有疑问,这个棋谱是怎么来的?我们会在第九章进行解答。在第九章我们将学习蒙特卡罗方法,我们会用这个方法构建一个会下棋的AI,也会生成AI之间的对弈棋谱。